
Unlocking Efficiency: Analyze Unstructured Data Using LLMs
Explore how fine-tuned LLMs transform business efficiency by deeply analyzing unstructured data for actionable insights.


Key Takeaways
Fine-tuning LLMs specifically for business applications significantly enhances their ability to analyze and extract actionable insights from unstructured data.
Advanced technologies like NLP and machine learning are essential for efficiently processing the vast and varied forms of unstructured documents businesses encounter.
The application of LLMs extends beyond text analysis to include tasks like risk assessment in insurance underwriting, demonstrating their transformative potential across industries.
Strategic integration of a large language model, guided by selecting appropriate tools, fostering partnerships, and enhancing user access, is crucial for leveraging the full potential of unstructured data analysis.

This post is sponsored by Multimodal, a Generative AI company that helps organizations automate complex, knowledge-based workflows using AI Agents. Each AI Agent is trained on clients' proprietary data and for their specific workflows, enabling easy adoption and maximum efficiency.
Today, most businesses automate basic processes. Despite this, they often fail to achieve optimum efficiency. This is mainly because highly scalable logic-oriented automation, though helpful, rarely solves industry-specific problems that require deeper understanding from valuable unstructured sources.
One of the biggest such problems is analyzing unstructured documents, which make up the majority of all business data.
Unstructured documents are documents that do not follow a predefined structure or schema. Examples include text-heavy files, such as emails, PDFs of contracts, social media posts, customer reviews, healthcare prescriptions and records, insurance documents, and more.
Unlike structured data, which is stored in fixed fields within records or files (like databases), unstructured data is not organized and often contains various forms of information, making it challenging to process and analyze using traditional data tools and algorithms.
Challenges in Analyzing and Extracting Insights from Unstructured Documents
1. Volume: Businesses generate a staggering volume of unstructured data every day. 90% of all data is unstructured, and processing so much data is a feat on its own.
2. Variety: Unstructured data also comes in various formats, adding another layer of complexity. Making sense of it requires tools and technologies with an almost human-level understanding of language.
3. Lack of Structure: The absence of a defined structure often makes conventional data analysis tools and techniques, which rely on a predictable and organized format, ineffective at handling unstructured documents. This necessitates the use of more sophisticated AI and machine learning models, such as Large Language Models.
4. Contextual Understanding: Unstructured data often contains idioms, nuances, sarcasm, and context-specific language that can be difficult for algorithms to interpret. Ensuring an accurate understanding of such data requires context-aware processing capabilities - an area where even the most advanced AI models sometimes struggle.
5. Data Quality and Consistency: The consistency of insights derived from unstructured data heavily depends on its quality. Inconsistencies, ambiguities, and errors – all common in unstructured documents – can lead to inaccurate analyses and potentially misleading conclusions. Cleaning and curating this data, on the other hand, can be a resource-intensive task.
6. Privacy and Security: Analyzing unstructured data involves processing sensitive or personal information, raising significant privacy and security concerns. Ensuring compliance with data protection regulations (like GDPR in Europe or CCPA in California) while extracting valuable insights from unstructured documents is a critical challenge for businesses.
Overcoming these challenges requires a combination of advanced technologies, including natural language processing (NLP), machine learning, and specifically tailored algorithms designed to interpret, categorize, and analyze unstructured data efficiently.
Limitations of Standard LLMs for Business-Specific Needs
Given the advancements in LLMs and their applications, it's important to understand the challenges businesses face when employing standard, off-the-shelf LLMs for tasks like analyzing unstructured documents.
1. Contextual Understanding: Standard LLMs often struggle with contextual nuances specific to certain businesses or industries. For example, legal contracts or medical records contain specialized terminology and complex relationships that LLMs might misinterpret without additional, domain-specific pretraining. This limitation can lead to inaccuracies in data understanding and generation, potentially impacting decision-making processes.
2. Adaptability to Specific Tasks: LLMs are generalists; they are designed to perform a wide range of NLP tasks but may not excel in specialized tasks without fine-tuning. Businesses often require precise analyses tailored to specific objectives, such as identifying actionable insights from customer feedback or predicting trends from market reports. Achieving this level of specificity with a standard LLM may require extensive customization, which can be resource-intensive.
3. Data Privacy and Security Concerns: Using LLMs for processing sensitive documents raises concerns about data privacy and security. Businesses dealing with confidential information, such as personal data or proprietary knowledge, must ensure that their use of LLMs complies with regulations like GDPR or HIPAA. Standard LLMs, especially those operated as cloud services, might not offer the necessary guarantees for data protection.
4. Scalability and Performance Issues: While LLMs are capable of processing large volumes of data, the computational resources required for such tasks can be substantial. Businesses with extensive archives of unstructured documents might find that standard LLMs are not cost-effective for large-scale analysis.
Examples of Challenges in Processing Unstructured Documents
Contracts and Legal Agreements: Analyzing contracts with a standard LLM can be particularly challenging due to the legal language's complexity and the need for precise interpretation. Key details such as obligations, rights, and penalties must be extracted accurately to avoid misinterpretation.
Emails and Customer Communications: Customer communications, including support tickets and emails, are often unstructured and can vary widely in tone, style, and content. Standard LLMs might struggle to accurately categorize these communications, extract relevant information, or gauge sentiment without specific training on similar datasets.
By overcoming these obstacles, businesses can unlock the full potential of LLMs to gain a competitive edge in the data-driven digital landscape.
The Concept of Fine-tuning and Its Importance
Fine-tuning large language models to analyze unstructured documents is a pivotal step in enhancing their performance to meet specific business needs and overcome the generic nature of their initial training. It involves adjusting the pre-trained models to better understand and generate text related to particular domains, tasks, or datasets.
Fine-tuning not only makes LLMs more versatile but also significantly improves the model’s performance, efficiency, accuracy, and relevance to specialized applications.
Fine-tuning is a process where a pre-trained LLM is further trained on a smaller, domain-specific dataset. This training phase is shorter and requires less data than the initial training phase, leveraging the model's existing knowledge base. The importance of fine-tuning lies in its ability to adapt LLMs to the nuances of specific contexts, languages, and terminologies that were not part of their original training.
For instance, an LLM trained on general web text might not perform well on legal documents or medical records without fine-tuning. Through the fine-tuning process, businesses can tailor LLMs to their unique challenges, enhancing the model's predictive capabilities.
Techniques for Fine-Tuning LLMs
Supervised fine-tuning (SFT)
Supervised fine-tuning is a common approach to adapting a pre-trained model to a specific task. It involves training the model on a labeled dataset, where the model learns to predict the correct label for each input.
Reward Modeling: (RLHF) and (DPO)
Reward modeling is another approach to fine-tuning, which involves training the model to optimize a reward function. This function is typically defined based on human feedback, hence the term Reinforcement Learning from Human Feedback (RLHF).
Direct Preference Optimization (DPO) is a similar approach, where the model is trained to optimize a reward function defined based on direct comparisons of different model outputs.
Parameter Efficient Techniques for Fine-Tuning LLMs
Low-Rank Adaptation (LoRA)
LoRA is a technique that updates a small subset of the pre-trained model and its parameters while keeping the majority of them fixed. This approach allows for efficient fine-tuning, as it reduces the computational resources needed by focusing on adjusting only the most impactful parameters.
LoRA works by introducing trainable low-rank matrices into the transformer layers of LLMs, which enables the model to adapt to new tasks with minimal changes to its original structure. The beauty of LoRA lies in its balance between flexibility and efficiency, making it possible to fine-tune LLMs for specific applications without the need for extensive retraining.
Quantized Low-Rank Adaptation (QLoRA)
QLoRA is an efficient fine-tuning process that reduces memory usage enough to reduce both memory and quantity of GPUs while preserving full 16-bit fine-tuning task performance. QLoRA backpropagates gradients through a frozen, 4-bit quantized pretrained language model into Low-Rank Adapters (LoRA).
QLoRA introduces several innovations to save memory without sacrificing performance: (a) 4-bit NormalFloat (NF4), a new data type that is information-theoretically optimal for normally distributed weights (b) Double Quantization to reduce the average memory footprint by quantizing the quantization constants, and (c) Paged Optimizers to manage memory spikes.
QLoRA was used to fine-tune more than 1,000 pre-trained language models, providing a detailed analysis of instruction following and chatbot performance across 8 instruction datasets, multiple model types (LLaMA, T5), and model scales that would be infeasible to run with regular fine-tuning (e.g. 33B and 65B parameter models).
The results show that QLoRA fine-tuning on a small high-quality dataset leads to state-of-the-art results, even when using smaller models than the previous SoTA.
Practical Applications of a Fine-Tuned Model
Fine-tuned LLMs are now pivotal in conducting sophisticated contract analysis, enhancing various business functions, and even streamlining insurance underwriting processes. These applications underscore the transformative potential of large language models across industries, offering unprecedented efficiency, accuracy, and depth in data analysis.
Contract Analysis at Scale and Deep Contractual Analysis
Contract analysis is a critical yet traditionally labor-intensive process, requiring meticulous attention to detail to interpret obligations, rights, amendments, potential liabilities, and more. Fine-tuned large language models can automate this process, significantly reducing the time and human resources needed.
By training on domain-specific legal language and contract structures, LLMs can identify, extract, and summarize key contractual elements across vast document repositories.
At-scale contract abstraction allows businesses to manage thousands of contracts efficiently, identifying specific clauses, renewal dates, and compliance requirements without manual review. This capability is particularly beneficial for sectors with high volumes of standardized contracts, such as telecommunications, real estate, and SMB agreements.
Deep contractual analysis delves into complex, multifaceted agreements that govern long-term business relationships.
Fine-tuned models can navigate through extensive legal documents to pinpoint specific terms, amendments, and their implications, facilitating a deeper understanding of contractual landscapes.
Applications in Insurance Underwriting

The use of AI in Insurance will be led by large language models and their underlying technology. Fine-tuned LLMs will play a key part in making the industry more efficient.
In the insurance sector, instruction fine-tuning of LLMs is becoming instrumental in automating and enhancing the insurance underwriting process. By analyzing vast arrays of unstructured data from medical records, claim histories, and legal documents, fine-tuned LLMs can assess risks more accurately and tailor insurance policies to individual needs.
Risk Assessment: LLMs can process detailed personal and medical histories to determine insurance premiums and coverage limits more accurately, reflecting the actual risk posed by each applicant.
Fraud Detection: Training on patterns indicative of fraudulent activity enables LLMs to flag potential fraud in claims or applications, safeguarding against financial losses.
Regulatory Compliance: LLMs ensure policies and practices comply with ever-changing insurance regulations, minimizing legal risks and maintaining operational integrity.
McKinsey highlights the seismic impact AI and related technologies, including LLMs, will have on the insurance industry, from policy pricing to claims processing.
For example, leading insurers now use granular segmentation of risk, incorporating external data through advanced modeling techniques, to improve pricing and reduce losses. This approach has enabled insurers to offer quick quotes for low-risk customers, dramatically improving the underwriting process's speed and efficiency.
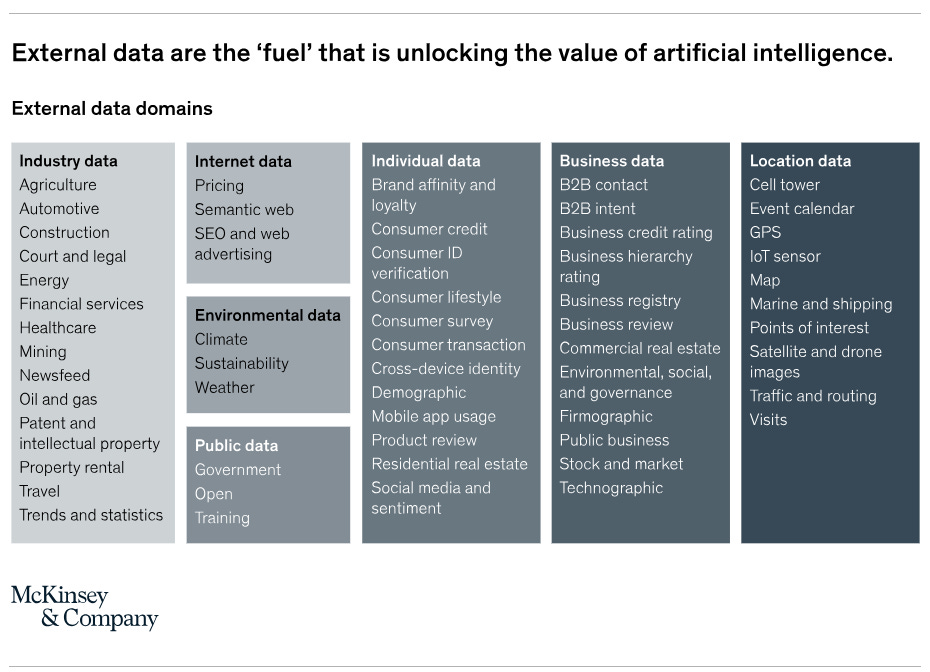
Some US P&C insurers have harnessed external data to transform their quote-to-issue process, leading to significant improvements in policy binding rates and risk discrimination at the acquisition funnel's top.
Similarly, midsize insurers serving small commercial segments have developed digital platforms that use advanced analytics and third-party data to deliver quotes and bind policies in minutes, starkly contrasting to the traditional, lengthy process.

I also host an AI podcast and content series called “Pioneers.” This series takes you on an enthralling journey into the minds of AI visionaries, founders, and CEOs who are at the forefront of innovation through AI in their organizations.
To learn more, please visit Pioneers on Beehiiv.
Looking Ahead
By addressing the inherent challenges of analyzing unstructured documents—ranging from volume and variety to the lack of structure and privacy concerns—LLMs offer a sophisticated solution that marries advanced technology with strategic business needs.
Through fine-tuning processes like Supervised Fine-tuning and Reward Modeling, businesses can tailor a pre-trained model to specific tasks, enhancing their contextual understanding and adaptability.
Real-world applications across contract analysis, customer communications, and insurance underwriting demonstrate the transformative potential of these models.
In the future, the strategic integration of LLMs into various business processes will be crucial for maintaining competitive advantages and fostering innovation. The journey towards fully leveraging unstructured data is complex. Still, with the continued advancement of LLMs and a commitment to refining these models, businesses can unlock the full potential of their data, driving growth and success.