
Pre-training Vs. Fine-Tuning Large Language Models
Explore the roles of pre-training and fine-tuning for large language models, their benefits, real-world applications, and a comprehensive comparison.


Key Takeaways
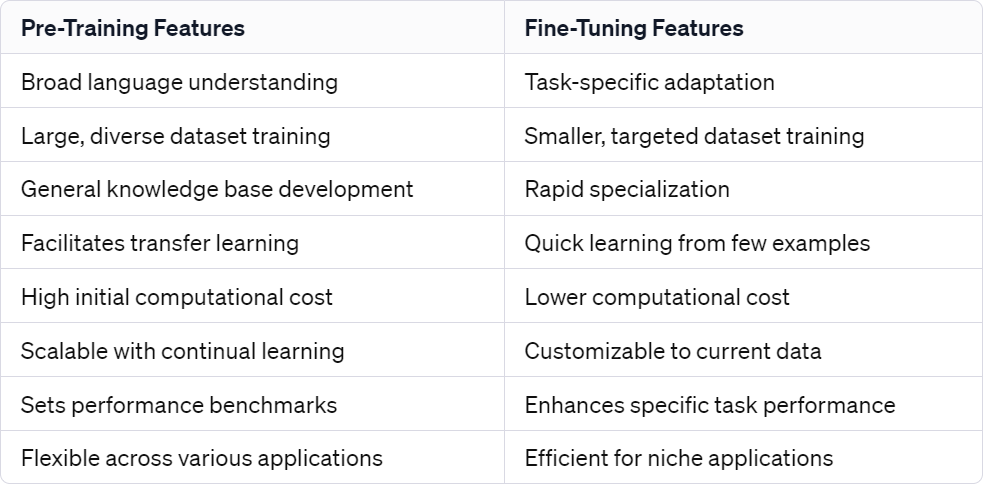
Pre-training is foundational for LLMs, providing a broad language understanding from vast datasets, enabling models to generate coherent responses across topics, and facilitating transfer learning.
Fine-tuning tailors pre-trained models to specific tasks or industries, enhancing their performance on particular applications and allowing them to learn efficiently from smaller, specialized datasets.
Pre-trained models offer cost-effectiveness and flexibility, allowing for scalable improvements and continuous pre-training with new data, often setting benchmarks in various NLP tasks.
Fine-tuning benefits include task specialization, data efficiency, faster training times, model customization, and resource efficiency, particularly beneficial for niche applications and continuous improvement.
Ethical challenges arise from potential biases in pre-training datasets, requiring mitigation techniques, while fine-tuning allows for precision in high-stakes fields such as healthcare and finance.
Real-world applications of pre-training include broad services like translation and content moderation while fine-tuning is used for specialized tasks by niche-market startups.
The strategic choice between pre-training and fine-tuning reflects the level of generalization vs. specialization a business needs, balancing broad competence with in-depth performance.
Pre-training is a long-term investment for versatile, foundational language models suitable for larger companies, whereas fine-tuning provides quick, precise solutions for specific business needs, benefiting companies of all sizes.

This post is sponsored by Multimodal, an NYC-based startup setting out to make organizations more productive, effective, and competitive using generative AI.
Multimodal builds custom large language models for enterprises, enabling them to process documents instantly, automate manual workflows, and develop breakthrough products and services.
Visit their website for more information about transformative business AI.
The evolution and capabilities of large language models (LLMs) have evolved rapidly, emphasizing the diverse landscape of machine learning. These sophisticated models, capable of understanding, generating, and interpreting human language, are at the forefront of AI research and application. The training methodologies are crucial to the effectiveness of these models.
This article delves into the two predominant approaches: pre-training and fine-tuning. Pre-training involves teaching the model a broad understanding of language from massive datasets while fine-tuning adapts this knowledge to specific tasks or domains. Each method has distinct advantages, challenges, and uses, shaping the landscape of LLMs.
Pre-training Large Language Models
Pre-training is the initial stage in the development and training process of LLMs, where the model learns from a vast corpus of text data. It's akin to giving the model a general education on language, culture, and knowledge. This phase is foundational, setting the stage for any specialized learning that follows.
Benefits of Pre-training:
1. General Knowledge Base: By analyzing a vast corpus of text, pre-trained models develop an understanding of grammar, idioms, facts, and the subtleties of different contexts. This comprehensive knowledge base and in-context learning allows them to generate coherent and contextually appropriate responses across a variety of topics, akin to how a well-read person can converse on many subjects.
2. Transfer Learning: Once a model has been pre-trained, it can apply its learned language patterns to new datasets, which is particularly useful for tasks with limited data. This ability to transfer learning means that models require fewer examples to understand the nuances of a new task, as they can draw parallels from their pre-training experience.
3. Cost-Effective: Pre-training a language model requires substantial computational resources and data, but once this phase is completed, the same model can be reused across countless applications. This amortizes the initial investment over many tasks, making it more cost-effective than training individual models for each new task.
4. Flexibility: The broad understanding obtained during pre-training allows for the same model to be adapted for tasks as diverse as summarization, classification, and generation. This flexibility makes pre-trained models invaluable tools in the toolkit of researchers and developers.
5. Improved Performance: Pre-trained models often set new benchmarks in natural language processing tasks. This is because the extensive pre-training phase equips them with a nuanced understanding of language, which is then refined during fine-tuning to produce state-of-the-art results on specific tasks.
6. Scalability: As new data becomes available, pre-trained models can be further trained (a process sometimes referred to as "continual pre-training") to improve their understanding and performance. This scalability ensures that the model remains relevant and improves over time as more information is fed into it.
Fine-Tuning Large Language Models
Fine-tuning, on the other hand, is the process of adapting a pre-trained model to perform well on a particular task. It involves training the model on a smaller, task-specific dataset, allowing for specialized understanding and performance improvements.
Benefits of Fine-tuning:
1. Task Specialization: Fine-tuning adjusts the model's parameters specifically for the nuances of a particular task, allowing it to excel in areas like medical diagnosis from text, legal document analysis, or customer service interactions. This specialization makes the model much more effective than a general-purpose pre-trained model would be on its own.
2. Data Efficiency: During fine-tuning, the model quickly learns the specifics of a new dataset, which means that companies and researchers can build powerful AI tools even with a relatively small amount of task-specific data. This efficiency is crucial for niche applications where large datasets are not available.
3. Faster Training Times: Fine-tuning typically involves adjusting the final layers of a pre-trained model to a specific task, which can often be done in a fraction of the time and with far less computational power than the initial pre-training. This makes the development cycle for new AI applications much faster.
4. Customization: By fine-tuning a model, it can adapt to the specific language and terms of any domain (legal, medical, or technical, for example). This customization ensures that the model's responses are accurate and relevant to the specific field it is being used.
5. Continuous Improvement: Fine-tuning can be repeated as new data becomes available, allowing the model to stay up-to-date with the latest information and trends. This is crucial in fields where knowledge and best practices are constantly evolving.
6. Resource Efficiency: Since fine-tuning requires less computational power and data than pre-training, it is a more sustainable approach for developing AI applications. This resource efficiency is particularly important as the world becomes more conscious of the environmental impact of computing.
Pre-training Large Language Models: Extended Benefits and Applications
Beyond the foundational benefits, pre-training equips LLMs with a kind of 'intuition' for language nuances, which can be likened to the intuitive grasp a human has from being exposed to language over many years.
Pre-trained models can predict and generate coherent and contextually appropriate language, making them invaluable in tasks requiring language generation, such as creative writing tools or conversational agents. For instance, GPT-3 by OpenAI, with its vast pre-training, has been used to create interactive chatbots, draft emails, and even generate coding scripts, demonstrating its versatile utility across various fields.
Advanced Challenges and Ethical Considerations
The vast datasets used in pre-training also pose ethical challenges, as they can mirror societal biases present in the training data. This has led companies like Google and IBM to invest heavily in bias mitigation techniques.
Moreover, the environmental impact of pre-training, due to its intensive computational requirements, has become a concern. Efforts are underway to create more energy-efficient models and training processes, with initiatives like Google's use of tensor processing units (TPUs) that optimize computational efficiency.
Fine-Tuning Large Language Models: Extended Benefits and Sector-Specific Applications
Fine-tuning enables LLMs to excel in sectors requiring high precision, such as finance and healthcare. For example, a fine-tuned model on financial reports can assist in detecting fraud more effectively than generic models.
In healthcare, models like IBM Watson have been fine-tuned to parse medical research and patient data to assist in diagnosis and treatment planning, showcasing the potential for highly specialized applications of LLMs.
Strategies to Mitigate Challenges and Enhance Fine-Tuning
To combat overfitting, techniques such as regularization and cross-validation are employed during the fine-tuning process. Additionally, transfer learning strategies are used to retain the general knowledge from pre-training while adopting new information.
This balance is critical, as seen in the fine-tuning of BERT for NLP tasks, which Google has leveraged to improve its search algorithms, showing how fine-tuning can significantly enhance specific functionalities.
Comparative Analysis and Real-World Examples
In the tech industry, companies like Facebook, Microsoft, and Amazon use pre-training to develop the foundational AI for services like translation and content moderation. For instance, Microsoft’s Translator has been pre-trained in numerous languages and then fine-tuned with specific bilingual data to improve its translation accuracy.
On the other hand, fine-tuning is often used by startups specializing in niche markets, such as Replika in personalized conversational agents or Grammarly in writing assistance, where the focus is on a specific task performance.
There are also examples of hybrid models. These usually are pre-trained and then fine-tuned to achieve excellent sector-specific results.

Cost and Resource Implications with Industry Examples
While pre-training is a resource-intensive process, as seen with models like GPT-3, the long-term benefits often offset the initial investment for major companies. Fine-tuning, being more task-specific, requires less computational power and can be a cost-effective strategy for companies focusing on specific applications.
For instance, Duolingo uses fine-tuned models to personalize language learning experiences, which is more resource-efficient compared to building a model from scratch.
Balancing Act Between Generalization and Specialization
The choice between pre-training and fine-tuning also involves a strategic decision about the level of generalization versus specialization desirable in a model. Pre-training aims for a wide-ranging competence, while fine-tuning seeks depth in a narrow field.
In cases like customer service bots used by companies such as Zendesk or Salesforce, a balance is crucial: the bot must understand a broad range of queries but also provide detailed assistance within the context of the company’s services.
Real-world Impact and Success Metrics
The success of pre-training and fine-tuning can be measured by their impact on real-world applications. Pre-trained models have enabled the creation of versatile tools like OpenAI's Codex, which assists programmers by suggesting code snippets.
In contrast, fine-tuned models have led to highly specialized tools such as DeepL’s translator, which, despite its smaller size compared to tech giants, competes on translation quality through effective fine-tuning.
Business Applications of Fine-Tuning vs. Pre-training
The business implications of fine-tuning versus pre-training large language models are profound, reflecting the divergent needs of enterprises across industries. Pre-training provides a strong foundational understanding of language, which is universally beneficial. However, the real value for businesses often lies in fine-tuning, which tailors models to specific industry needs, customer interactions, and proprietary data.
For example, in the finance sector, companies may use pre-trained models for general tasks like sentiment analysis of market news. However, they fine-tune models to comply with financial regulations, understand industry jargon, and analyze company-specific reports. This targeted adaptation can lead to more accurate risk assessments and investment insights, directly impacting a company's bottom line.
In customer service, businesses often start with a pre-trained model capable of understanding and generating human-like text. Fine-tuning these models with company-specific data, including product details, support FAQs, and past customer interactions, creates a chatbot that provides personalized and accurate support, enhancing customer satisfaction and retention.
The retail industry also benefits from fine-tuning. While a pre-trained model can handle general customer queries, fine-tuning allows for a model to recommend products based on past purchasing data and predict shopping trends, which can be used to tailor marketing strategies and inventory management.
The strategic choice between investing in pre-training versus fine-tuning is influenced by the nature of the business, the uniqueness of its data, and the specificity of the tasks it needs to perform. Larger corporations with diverse AI needs may invest heavily in pre-training to create versatile models. At the same time, startups or companies with a narrow focus may find fine-tuning existing models to be more cost-effective and just as beneficial.
Conclusion
For businesses, the key to leveraging large language models lies in understanding the distinct value of pre-training and fine-tuning. Pre-training offers a broad linguistic foundation, making models versatile and widely applicable, which is a sound long-term investment for larger companies with diverse AI applications.
In contrast, fine-tuning is crucial for adapting models to specific business needs, providing precise, industry-specific solutions that can quickly be brought to market. As AI continues to advance, businesses that skillfully apply both pre-training and fine-tuning will gain a competitive edge, driving innovation and achieving greater efficiency in their operations.