
The Impact of Wizard and Falcon on Open-Source LLM Development
Falcon and Wizard expand LLM capabilities with their novel training methods. Here's a detailed comparative study of the two models.


Key Takeaways
WizardLM uses a novel model training method called Evol-Instruct, where a set of instructions converts into a more complex set of instructions. This method uses LLMs, instead of humans, to automatically produce large quantities of open-domain instructions of varying complexity.
The performance of WizardLM is highly comparable to that of GPT-4, achieving 100% performance on 18 different skills and even surpassing GPT-4 in some skills.
TII created the Falcon-40B and Falcon-7B models. Falcon-40B is the main model, which contains 40 billion parameters.
TII trained Falcon-40B almost entirely on high-quality data from the RefinedData dataset and a small amount of curated data. The Falcon models have impressive performance (ranking first on the Open LLM leaderboard by hugging face) and are computationally efficient.
Both models are advancing LLM development by using new approaches to improve their training processes and how well they perform.
The Falcon models are open-source and free to use for commercial use, inviting the LLM community to explore different use cases.
There's potential for further exploration of the Evol-Instruct model training method and the RefinedWeb dataset to develop models that outperform GPT-4.

This post is sponsored by Multimodal, a NYC-based development shop that focuses on building custom natural language processing solutions for product teams using large language models (LLMs).
With Multimodal, you will reduce your time-to-market for introducing NLP in your product. Projects take as little as 3 months from start to finish and cost less than 50% of newly formed NLP teams, without any of the hassle. Contact them to learn more.
We keep hearing about the GPT models by OpenAI, but recently, a couple of open-source models have demonstrated tremendous performance.
These models use an innovative approach to the training process, leading to improved proficiency in various skills.
But how exactly did they do that?
What Are the Wizard and Falcon Models?
The Wizard and Falcon models have taken the world of open-source large language model (LLM) development by storm.
Both models have introduced new methods to improve training LLMs, which leads to better performance. The performance of these models has surpassed that of many of the other open-source LLMs currently available.
These models are quite a step forward in advancing the capabilities of LLMs, and we’ll look at why that is.
WizardLM Overview
A research team from Microsoft and Peking University released WizardLM on May 26, 2023, and used LLaMA (Large Language Model Meta AI) as the base. What’s fascinating about the Wizard models is that they use a new method called Evol-Instruct for the training process.
This method can improve the performance of LLMs by dealing with the issue of creating a lot of instruction data.
In other LLMs, like GPT3, the instruction data has to be manually inputted. However, this approach isn’t appropriate on a larger scale. This is especially true when generating massive amounts of instruction data for the LLM.

Evol-Instruct overcomes this issue by taking a starting set of instructions and converting them into a more complicated set. These newly generated instructions are of higher quality than manually created instructions. The model then utilizes these instructions during the fine-tuning process.
Moreover, this method produces massive amounts of open-domain instructions of varying difficulty levels automatically, using LLMs rather than humans.
Applications of WizardLM
We know that Wizard is taking this novel approach to generate instruction data, but what can it actually do?
In the graph below, we can see how WizardLM and GPT-4 performed at various tasks:

The developers of WizardLM tested their model against the current flagship LLM, GPT4, in 24 different skills. Even for more technical and demanding skills like academic writing, chemistry, and physics, WizardLM can outperform GPT4. It’s a good sign that Evol-Instruct is a practical option for training LLMs for more difficult tasks.
WizardLM can also generate code that significantly outperforms the LLaMA models, which can support software developers with programming-related issues. Additionally, Wizard can translate languages, summarize texts, generate creative writing, and many others. It can carry out many of the same tasks that GPT-4 can.
What Implications Does Wizard Have for Open-Source LLM Development?
Other developers are already jumping on the WizardLM bandwagon. Currently, there are 116 WizardLM-based models on Hugging Face, with this number only increasing as time passes.
Evol-Instruct opens up new possibilities for the future of open-source LLM development, with WizardLM being living proof of how Evol-Instruct can improve performance when handling difficult tasks.
As code generation is a key aspect of LLMs, the WizardLM developers created WizardCoder, a model specifically designed to deal with more difficult coding problems using their new Evol-Instruct method for training.
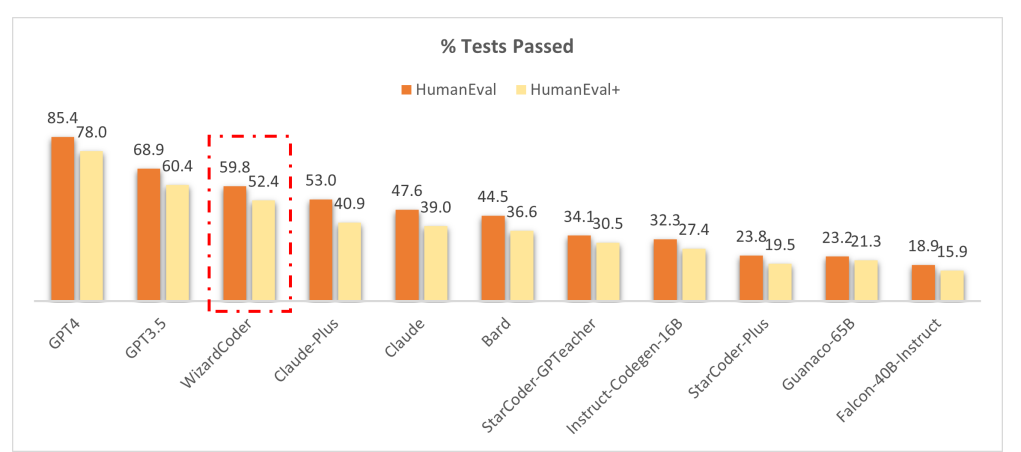
WizardCoder performs better than almost any other model besides GPT-3.5 and GPT-4. Notably, models like Claude and Bard are closed-source. Having powerful open-source models like WizardLM and WizardCoder improves collaboration between developers and is more likely to lead to further advancements in LLMs.
Current Limitations of Wizard
While the WizardLM models are great, we can’t just overlook their limitations in their current state. Evol-Instruct is definitely a big step forward in automating instruction data generation, but that doesn’t mean the whole process can be fully automated.
There still needs to be humans checking the quality of the instruction data, as the quality will directly affect the quality of the training data used for the model.
LLMs like GPT3 and GPT4 have a big issue because they generate hallucinated datasets that might carry over into the training process. The model makes up hallucinated datasets that aren’t factual. As a result, this negatively affects the model’s accuracy and reliability.
WizardLM's model doesn’t seem to address this issue in particular with its new approach, Evol-Instruct. Likely, this is still an issue that LLM developers are looking into.
Falcon Overview
Developed by Technology Innovation Institute (TII), there are currently 2 Falcon base models available: Falcon-7B and Falcon-40B. These models are just as good as closed-source models. With TII making the Falcon LLMs open-source, they invite developers and researchers to explore their usage further.
The Falcon-7B contains 7 billion parameters and uses 1.5 trillion tokens for training, while the Falcon-40B contains 40 billion parameters and uses 1 trillion tokens for training. LLaMA, for example, contains 65 billion parameters, or 25 billion more parameters than Falcon-40B. This means the Falcon-40B uses fewer computational resources, like memory.
As we mentioned earlier, the quality of training data drastically affects the LLM's performance, with GPT4’s issue dealing with hallucination prompts carrying over into training. TII explicitly states that this is exactly what they want to focus on,
“quality data at scale.”
Training data used for Falcon LLMs involved scraping data from RefinedWeb. This dataset uses various filters to extract large quantities of high-quality data while mostly avoiding curated sources.

Traditionally, the consensus among LLM developers is that there isn’t enough high-quality data and that curation is necessary. Falcon and RefinedWeb go against this agenda by showing that it’s certainly possible to train the LLM almost entirely on high-quality data.
Applications of Falcon
Similar to other LLMs, like the GPT models, Falcon LLMs can do the same tasks. Here is a quick overview of some use cases for Falcon:
Content generation: Content comes in many forms, including blogs, social media, and advertisements. Falcon can create content in seconds, saving time and providing ideas.
Solve difficult problems: Falcon can deal with complex problems by using logical thinking to devise a solution.
Chatbots: LLMs have seen wide usage in chatbots due to their NLP abilities. This helps provide better customer service, as chatbots can deal with customer issues 24/7.
Falcon is seeing usage in research areas, such as healthcare. Generally, these models have broad uses (as expected).
However, TII is focusing on how Falcon can automate less creatively challenging tasks, letting businesses focus on more pressing issues instead. Since Falcon is commercially available under an Apache 2.0 license, there are endless possibilities for developers and researchers to explore new ways to use these models.
How do the Falcon LLMs Compare to Other LLMs?

Hugging Face evaluated the Falcon LLMs against criteria such as common sense and distinguishing between factual/incorrect information. Falcon-40B ranked first on the Open LLM leaderboard, indicating Falcon-40B can outperform many other open-source LLMs when comparing them based on common tasks.
It’s also worth noting that Falcon-40B can exceed other models, despite using less computing power than other models during training.
What Implications Does Falcon Have for Open-Source LLM Development?
High-quality training data isn’t the only focus of the Falcon LLMs. They also use a smaller computing budget while maintaining high performance. TII stated,
“Falcon significantly outperforms GPT-3 for only 75% of the compute training budget”.
It can outperform GPT-3 efficiently while using a fifth of the compute at inference time. Combining its new approach to using mainly high-quality data for training while maintaining computational efficiency, Falcon has undoubtedly left its mark in the open-source LLM world. Especially considering that Falcon is commercially available, there’s much to explore.
As Falcon LLMs are computationally efficient, more researchers can explore the models due to their reduced cost compared to more demanding models.
Future of Open-Source LLM Development
The emergence of Falcon and Wizard has opened a lot of doors when it comes to open-source LLM development.
With Wizard’s Evol-Instruct, LLM performance on more challenging tasks is improving, as Wizard is already close to GPT-4 in terms of capabilities.
Falcon’s approach to using the RefinedWeb dataset to train the model on primarily high-quality data has shown the LLM development community that it’s certainly possible to train these models without relying on massive amounts of curated data.
With both open-source models, researchers can fine-tune them to optimize their performance and efficiency further. Evol-Instruct and the RefinedWeb dataset enable researchers to refine further and create new LLMs that may even outperform GPT-4 soon.