
Buy vs. Build LLMs: Which One Should You Choose?
Making the decision between buy vs. build LLMs is tough. Discover how you can make a more informed choice based on your needs and goals.


Buy vs. Build LLMs: Which One Should You Choose?
Key Takeaways
Pre-trained LLMs like GPT-4 offer high performance and highly advanced features with a monthly subscription. OpenAI constantly updates the models over time.
Pre-trained LLMs are highly efficient and cost-effective. These models require little technical knowledge to use. Prompt engineering is useful for getting better outputs from the model without having to train it yourself.
Open-source LLMs like LLaMA and BERT can be trained for specific applications like specialized chatbots and conversational systems, but this requires knowledge of machine learning and NLP.
Open-source LLMs promote collaboration and deeper exploration of how LLMs work, as seen by the WizardLM-based models on Hugging Face.
With pre-trained LLMs, data security and privacy are issues, as any sensitive information used as input data will be saved on the servers. Open-source LLMs provide full control over what data is used for training, with no third party involved.
Your decision should come down to your resources and goals. With expertise, budget, and time, you could train open-source LLMs for more specific use cases. Otherwise, a pre-trained LLM is convenient and easy to use.

This post is sponsored by Multimodal, an NYC-based startup setting out to make organizations more productive, effective, and competitive using generative AI.
Multimodal builds custom large language models for enterprises, enabling them to process documents instantly, automate manual workflows, and develop breakthrough products and services.
Visit their website for more information about transformative business AI.
Popular models like ChatGPT have made using pre-trained models seem like the most appealing option due to their ease of use and accessibility.
However, open-source LLMs are now emerging as a fresh option for users who want more control over their models, as seen with examples such as Wizard and Falcon.
Let’s look at the advantages of both pre-trained and open-source, along with guidance on how you should decide which one to choose.
Pre-trained LLMs (Buy LLMs)
As the name implies, these models have already undergone the training phase, with users only being able to access the end product. Pre-trained LLMs can also be considered “buy” LLMs, as they only require you to purchase a subscription to gain access.
Examples of commercial LLMs include ChatGPT developed by OpenAI. OpenAI offers a $20 monthly subscription, which gives you access to the more advanced GPT model, GPT-4, and various other advanced features like the code interpreter.
One advantage of pre-trained LLMs is that their providers are continuously improving their performance and capabilities. For example, OpenAI is expanding and evolving the performance of their GPT models, as seen below in the comparison of GPT 3.5 and GPT 4 on various exams.

These language models have been trained on massive amounts of text data and use unsupervised learning to make predictions.
The initial training stage consists of collecting large amounts of data, then preprocessing it to be used in the model. The model’s parameters are then adjusted to reduce the difference between predicted and actual outcomes.
Most pre-trained LLMs can perform various complex tasks, including:
Text summarization
Text generation
Content creation
Code generation
Sentiment analysis
Chatbots
The use cases for pre-trained LLMs like the GPT models are almost endless.
Benefits of Pre-trained LLMs
Pre-trained LLMs allow users to apply the language model to various use cases, with no effort on their part.
For example, by purchasing a subscription to ChatGPT, you can access highly advanced and powerful features that would be difficult to create when building your own language model.
The biggest advantage of pre-trained LLMs is their time and cost efficiency. It isn’t cheap to train your language model, and it isn’t a quick process either. Doing so would require you to collect massive training datasets, preprocess them, train the models, and evaluate and optimize their performance over time. PrLMs remove all the hassle.
Additionally, pre-trained LLMs like the GPT models provide convenience in terms of integration. ChatGPT has an API available that lets developers easily integrate the model into their own applications without understanding the process's more technical intricacies.
Moreover, if you aren’t happy with the output quality the pre-trained LLM is returning, you could use prompt engineering to improve results without tinkering with the underlying model.
With ChatGPT, for example, prompt engineering comes down to creating more specific and detailed prompts that optimize the model’s output.
Now that we know why pre-trained LLMs are an effective and popular choice among many users, let’s look at an alternative option: open-source large language models.
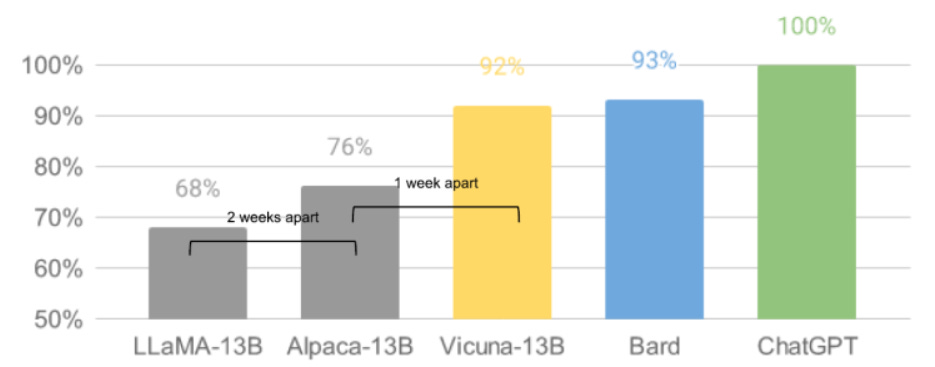
Open-Source LLMs (Build LLMs)
Contrary to pre-trained LLMs, open-source LLMs allow users to train and fine-tune the model to suit their needs. These LLMs have their entire code and structure publicly available. This allows developers to adjust the LLM for more specialized use cases that may not be possible with pre-trained LLMs.
Some examples of open-source LLMs include:
BERT: Developed by Google in 2018, Bidirectional Encoder Representations from Transformers (BERT) can understand the context of a word by reading in both directions, left and right.
LLaMA: Meta released the LLaMA model weights in February 2023, and is another open-source model gaining attention in recent months. It’s able to deliver high performance on various tasks.
Falcon: Technology Innovation Institute developed the Falcon-40B and Falcon-7B models. These models took an innovative approach to model training by using mainly high-quality data.
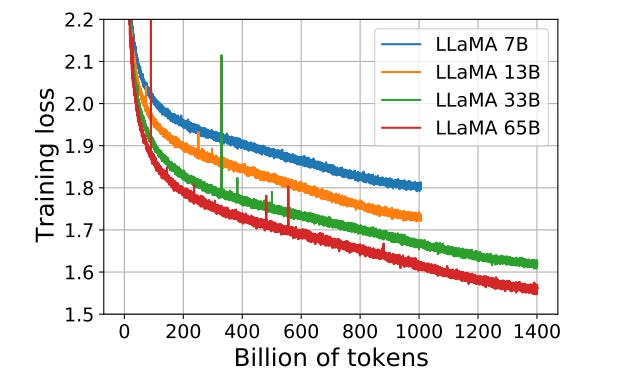
Open-source models offer high performance, with models such as the LLaMA model reaching training loss values as low as 1.6.
Frameworks like Hugging Face’s Transformers allow users to work with a starting point, and fine-tune the model toward specialized applications and using their own datasets.
While pre-trained LLMs offer a more out-of-the-box solution, open-source LLMs only provide the initial code and architecture as a starting point. Training open-source LLMs requires highly specialized technical knowledge in machine learning and natural language processing (NLP), massive amounts of training data, and a lot of computational resources.
We mentioned before that convenience is a major appeal of open-source LLMs. Not having to worry about the training data and computational resources is a big reason for that.
So what’s the benefit of open-source LLMs if it’s such a hassle to train them?
Benefits of Open-Source LLMs
Open-source LLMs are more challenging to work with but offer greater flexibility and customization.
If you have a very specific task that you want to complete using LLMs, then an open-source LLM would allow you to train the model to deal with those specific needs. While pre-trained LLMs can still be fine-tuned for certain scenarios, open-source LLMs provide much more freedom.
In contrast to pre-trained LLMs, open-source LLMs provide higher control over the data used in training the language model, along with the ability to adjust the model architecture. You can train the model on your voice and documents so that it produces more accurate results for your specific use-case.
They explicitly mention that they use user input as training data to further improve the model.
With open-source LLMs, you don’t have to worry about these types of issues. You have full control over what training data is used, which means none of your data is shared with a third party. Open-source LLMs provide better security measures as a result.
Additionally, open-source LLMs promote a sense of collaboration between developers all around the world. On Hugging Face, there are currently 135 WizardLM-based models, indicating that developers are exploring different ways to train open-source LLMs and find new applications.
Which One Should You Choose?
Now that we know how pre-trained and open-source LLMs differ, we can start to consider which type of model might be better for you.
A pre-trained model could be a good option if you’re looking for an LLM that you can start working with immediately without specialized NLP knowledge.
Even if you aren’t happy with the output of these language models, you can improve the output of pre-trained models without technical knowledge via prompt engineering instead of having to find better training data for your language model.
However, if you aren’t satisfied with the customization and flexibility offered by pre-trained models, then open-source LLMs might be the right choice for you.
With the right expertise and resources, you could train an open-source model for a specific type of use case, such as a more specialized chatbot or conversational system. For organizations that require niche and complex use cases, an open-source LLM would be the more appropriate choice.
Open-source LLMs are also much more transparent regarding the underlying code, architecture, and data used in the training process.
Factors to Consider in Your Decision
Let’s consider a few different factors that can influence your decision:
Budget: Typically, pre-trained models are much cheaper and less resource-intensive than open-source. You don’t have to train the language model from scratch when using pre-trained models, and you can still fine-tune them later on for specialization.
Time: Training an open-source model is much more time-consuming than using a pre-trained model. Models like GPT are available to use immediately without requiring the user to train the model first.
Privacy: When users input private and sensitive data into pre-trained models, this data is sent to the company’s servers, putting the user’s privacy at risk. With an open-source model, you could avoid entirely using sensitive data as training or input data.
Expertise: As we mentioned earlier, open-source models aren’t ideal if you want to use them without any LLM knowledge. If you’re well-versed in the area and want to explore further the intricacies of how they work, open-source LLMs are a great choice. Otherwise, pre-trained models let you start using them right away.
Customization: Open-source models provide more freedom in how you can customize them to suit your needs. By controlling the data used during the training phase, you’ll be able to directly influence the model’s behavior for more niche applications.
Overall quality: Both pre-trained and open-source LLMs deliver high performance, but open-source models have the edge if you train them for a specific task.
Making Your Final Decision
Ultimately, it depends on what you want out of your LLM experience.
If you have the budget, time, and expertise to train an open-source model for a specific use case, then it would be best to go down that route.
Otherwise, a pre-trained LLM is the best option if you still want access to state-of-the-art LLMs that are constantly improving.
It’s important to assess your current situation and goals before deciding which type of LLM is best for you.