
What is Intelligent Document Processing and How LayoutLM's Pre-Trained Model for Text and Image Understanding Works
Using AI to process structured or semi-structured documents eliminates the need for manual data entry. Here's how LayoutLM has unlocked the latest breakthroughs in document AI.


Key Takeaways
All companies across industries source valuable data from documents. This data helps businesses derive insights regarding their performance. For example, businesses record vendor spend data from invoices and push the data into an analytics software or spreadsheet program to understand which vendors are having the most significant impact on their spend.
Data is contained in documents that typically have both text and images. Scanned documents are more challenging to process than digital documents.
Every data analytics software or AI model needs data in a machine-readable format to process it. Humans have been manually performing document processing to capture this data and make it machine-readable for a long time. For example, college admissions departments extract financial data from college applicants’ financial aid forms and tax statements. Doing so is time-consuming, prone to errors, and expensive.
The biggest challenge businesses face when trying to implement AI solutions for their manual document workflow is the messy and uncategorized data spread across multiple types of documents. This data must be cleaned and prepared before it can be a valid input for AI-powered software.
Intelligent Document Processing or IDP is a cutting-edge way to process documents and make them machine-readable. These documents may be structured (e.g., checks) or unstructured (e.g., freeform word documents) and may contain difficult-to-parse information, handwriting, and even images.
Intelligent Document Processing platforms use AI to enhance data capture and extraction. They use NLP, NLU, and computer vision technology to understand and label each data field. IDP platforms also have a multi-stage process where they determine what piece of data is relevant for processing each document and what can be ignored.
Intelligent Document Processing is efficient, saves time and money, and reduces the need for a human workforce to process tedious documents. Moreover, it also helps organizations derive critical insights from data more accurately and faster. Due to these benefits, IDP has applications in finance, healthcare, education, travel, and many other industries.
While many IDP models exist today, one of the most effective is LayoutLM. This pre-trained model gives excellent results in form understanding, receipt understanding, and document-image classification. LayoutLM is the first IDP platform that improves document image understanding by using text and layout information in context with the images. This makes it state-of-the-art for processing visually rich structured or semi-structured documents.
LayoutLM’s subsequent versions, V2 and V3, are even better than V1 because they have trained on larger datasets. They also incorporate novel methods of image extraction and layout understanding.

This post is sponsored by Multimodal, a NYC-based development shop that focuses on building custom natural language processing solutions for product teams using large language models (LLMs).
With Multimodal, you will reduce your time-to-market for introducing NLP in your product. Projects take as little as 3 months from start to finish and cost less than 50% of newly formed NLP teams, without any of the hassle. Contact them to learn more.
Check out this scene from the biographical film Catch Me If You Can, released in 2002 by Steven Spielberg.
In this scene, teenager Frank Abagnale Jr., played by Leonardo DiCaprio, is seen forging checks and cashing them at the bank. It’s the 1960s, and human bank tellers are the only thing verifying bank checks. And for Frank, flirting is the key to distracting gullible tellers and making them cash his checks immediately.
In those days, even after encoding each check with MICR, it took two weeks or more to verify a check cashed in one location and routed to another. Why? Because humans take time to read and cross-check documents and postal services were slow (and still are). These shortcomings made it easy for Frank to defraud several banks in the US for over $2 million.
People like Frank still exist but committing check fraud isn’t as easy. The moment you submit a check to a bank, the bank can read the check and cross-verify the payee’s name, account number, signature, date, and account balance in seconds. If a check is fake, getting cash using it is impossible.
Automatic data extraction from checks using document capture technology is what makes this fast verification possible. Most banks use computers to scan and verify checks, bank statements, and identity documents. If you have ever deposited a check remotely using a smartphone, you know just how quickly it gets processed.
There is no scope for human error because all these documents are instantly converted to machine-readable formats. Then, machines take just a few seconds to cross-verify each document with the stored records.
Check capture is nothing new, but the technology behind it has become more sophisticated. Today, with Intelligent Document Processing, this tech is no longer limited to just capturing the words or numbers in well-structured documents like checks. Instead, computers can now capture, identify, and label data across many different types of documents and feed them to analytics software (such as Excel or a business intelligence dashboard) for further analysis.
What is Intelligent Document Processing? Why does it matter? Should you care about it as a business operator? Let’s explore these questions.
What is Intelligent Document Processing (IDP)?
Businesses have used data to derive insights to drive growth for decades. Today, AI-powered data analytics software does this job for millions of businesses. For example, invoices contain vendor spend information. This information is crucial for determining each vendor’s impact on a business.
AI-powered data analytics software is the best way to analyze this data. But the biggest challenge businesses face when implementing AI solutions is the messy and uncategorized data spread across different types of documents. OCR extracts this data and makes it machine-readable. But filtering, unifying, labeling, and categorizing the data is the next step to make it a valuable input for any AI-powered software. And this step involves human intervention for most enterprises.
While manual data entry has worked for businesses and still can, it is prone to errors, time-consuming, and costly. That is where intelligent document processing comes in.
Intelligent document processing is the modern approach to data entry and data processing. It involves using natural language processing, computer vision, and classical machine learning to extract, classify, and map data from documents before feeding it downstream to AI-powered analytics software or to human analysts for deriving insights.
IDP is efficient, fast, and free of human errors. IDP can process digital and scanned documents containing both images and text. That’s not to say humans have no place in a data entry workflow. However, because AI has made it faster and better, it is not practical for modern, fast-growing businesses to invest in a human workforce dedicated solely to document processing.
How is IDP Different from Optical Character Recognition (OCR) Technology?

Data capture technologies like optical character recognition (OCR) and computer vision have been used by businesses for a long time. We just discussed check capture, and that technology has been used for decades. But IDP takes data capture one step further by using more branches of AI.
How? Using a simple OCR can get you processable data from documents; it can capture words, phrases, numbers, and special characters from scanned or typed documents and convert them into a machine-readable form.
Likewise, computer vision technology can help computers process images, too. However, even after having this machine-readable data, you must label and categorize it to make it a useable input for any downstream data analytics your business might use.
Unlike optical character recognition, IDP does not just help with data extraction or capture. After making the data machine-readable, IDP platforms intelligently organize the data in the way an analytics software might need it. They also filter out any unnecessary data from a document and label each piece of data to signify what type of field it is. IDP platforms also integrate with your business’s automation software (e.g., CRM). This ensures you do not have to manually intervene to transfer the output from IDP to the analytics software. IDP is more of an end-to-end system than traditional OCR software.
IDP augments the way humans understand data. It can extract and process data from:
Structured Documents: formatting and layout are consistent between one document and another. Examples include surveys, tax forms like W9s, etc.
Semi-structured Documents: Formatting and layout are somewhat consistent but can vary. Examples include invoices, purchase orders, etc.
Unstructured Documents: No consistency in format or layout. Examples include freeform PDFs, word documents, etc.

{kind=link}
Structured documents are easier to process, while semi or unstructured documents are much more complex.
IDP is scalable and seamless and an essential tool for business operators. But before diving deeper into why nearly every business should use IDP in some form, let’s understand how it works.
What Are the Technologies That Enable IDP?
The two key technologies powering IDP platforms are:
Optical Character Recognition: Optical Character Recognition is responsible only for converting typed or handwritten data into machine-readable versions. It does not possess intelligence, so it cannot understand what each data piece means. Also, most documents today, such as PDFs or Word documents, are natively machine-readable and do not require OCR.
Document AI (Artificial Intelligence): The AI component relies on OCR to get machine-readable data if the data is not natively machine-readable. Then, using branches of AI like NLP, NLU, and computer vision, it extracts and classifies the data.
Most documents contain a lot of irrelevant data. Knowing what data to extract and what to reject is the real challenge. In a way, document AI is identical to how humans understand and process data.
For example, imagine your school transcript. Based on what you have learned at home and in school, you can figure out which part of the transcript shows your grades and which part shows your attendance, name, school, etc. If someone were to ask you to send them just your grades, you would look at the transcript, figure out what the grades are, copy them into an email, and send it over. You would not send over other information like school name or attendance. Similarly, intelligent document processing software classifies relevant data and rejects irrelevant data.
How Does Intelligent Document Processing (IDP) Work?
? - Benefits and use-cases of IDP in different industries")
.jpg){kind=link}
An IDP software works in several stages to extract and process documents. Here is what each of these stages entails:
Data Collection or Capture
Data collection is the first step of the document processing pipeline. Data can come from two types of sources: physical, like paper invoices, reports, letters, sheets, etc., or digital, like typed pdfs, emails, word documents, etc.
Physical Data Capture: IDP integrates with scanning hardware to extract physical data. It makes scanning these documents faster and better by improving image resolution.
Digital Data Capture: Just as physical data capture requires hardware integration, digital data capture requires software integration. An IDP platform will either have a built-in integration feature or will allow businesses to build their custom interfaces to support digital data capture.
Image Processing
Documents do not always contain just text. For document image information extraction, IDP uses OCR and computer vision technology. It scans the image in the document and uses image features like pixel data to make it machine-readable.
Pre-Processing
Before moving further in data processing, IDP platforms create structure from unstructured data. This involves noise reduction, cropping images, removing redundant data pieces, binarization, etc. After this stage, the document is cleaner and easier to parse than before.
Optical Character Recognition
IDP platforms do not just rely on one OCR tool to extract data. This is because different OCR tools can have specific weaknesses that negatively affect the quality of processed data. Using multiple OCR engines reduces the risk of inaccurate or missed data points.
Using NLP and Classification
The next step is identifying what data is relevant to the enterprise and what each data piece means. IDP systems use natural language processing to find the specific meaning of the textual information captured from the document. Using named entity recognition, IDP then decides which pieces of the text are useful for the next step in the document processing pipeline. This step is also called text-level manipulation.
Since not all the data is textual, IDP uses computer vision (which involves deep learning and convolutional neural networks) to make sense of the images and categorize them. Most IDP platforms are trained on real-world document image data to accurately recognize each image’s meaning.
Classification is one of the most critical stages of document processing. IDP platforms use machine learning to study vast datasets and understand how to categorize the information they have captured.
For example, an invoice can contain a name, bank account information, list items, addresses, and other components. All of these should be adequately categorized before being used to derive any insights from them. IDP does this using machine learning and NLP.
Usually, this step of automated classification is followed by manual intervention. At this stage, humans can further intervene and refine the categorized data or leave it as is. This human-in-the-loop process is vital for businesses because no machine learning model can handle all the edge cases that may occur. Therefore, it makes sense to let IDP handle most of the document processing but to leave the tricky edge cases for humans.
Extraction
Next comes the part where IDP systems derive valuable information from the categorized and refined data. IDP understands what kind of info your organization needs by using its training or fine-tuning. It only extracts information that it knows is relevant to your enterprise.
Validation
Not all the extracted data is always accurate. It needs to be verified successfully before moving further down the pipeline. IDP systems subscribe to external databases and lexicons to determine which information might be inaccurate or redundant.
The moment it spots such a data piece, the IDP platform sends it for human verification.
The output file after this stage is in XML or JSON format.
Integration
Finally, IDP platforms integrate with the downstream analytics software to enable insights and reports. The data is passed on using APIs.
A good IDP platform integrates seamlessly with downstream business software and systems like ERP, CRM, and ECM. Moreover, it also converts metadata into a human-readable format to allow for human interpretation and modification.
Applications of Intelligent Document Processing
IDP applications are far and wide in every industry. Here are some of the most common ones:
Finance: Invoices, Receipts, Bank Statements, Check Capture/Remote Deposit Capture
Healthcare: Case Histories, Test Reports, Prescriptions, etc.
Banking and Insurance: Claims, Loan Applications, Account Statements, Mortgage Records, Borrower Profile, etc.
Apart from these, industries like travel, education, tech, etc., use Intelligent Document Processing extensively to perform data operations accurately, cost-effectively, and quickly.
LayoutLM: How it Uses Machine Learning to Achieve Document Understanding
When discussing IDP’s various stages earlier, we discussed how good IDP platforms categorize and extract data. How does a system know which piece of data is what? For example, if an IDP model processes an invoice, how does it know which are the names, addresses, line items, and amounts?
The simple answer is through its machine learning training. A well-performing IDP model requires training (or at least fine-tuning) on a large dataset. Most IDP models receive training for text and image understanding tasks.
However, for the best possible classification of a visually rich document, IDP models need to consider the text and document layout information in context with the image information. Released in December 2019, LayoutLM is one of the first pre-trained models that considers all three effectively.
LayoutLM was first proposed in a research paper by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, and Ming Zhou. According to them:
[LayoutLM] is a simple but effective pretraining method of text and layout for document image understanding and information extraction tasks. (Source)
LayoutLM does not need much fine-tuning to start working. This makes LayoutLM perfect for businesses that do not have very large, labeled datasets to train on. Instead, these businesses can just fine-tune LayoutLM on a smaller dataset and achieve good model performance quickly (compared to the time and effort it would take to train the model from scratch).
How LayoutLM Works

{kind=link}
LayoutLM has received document-level pre-training to understand text, image, and layout information. It outperforms several benchmarks when evaluated on form understanding, receipt understanding, and document image classification.
Let’s consider a page of an invoice to understand how LayoutLM works. The first step is recognizing the text and identifying its location using OCR.
Optical Character Recognition in LayoutLM
Before LayoutLM can perform labeling or classification, the OCR engine recognizes the text and determines its location on a document using bounding boxes.
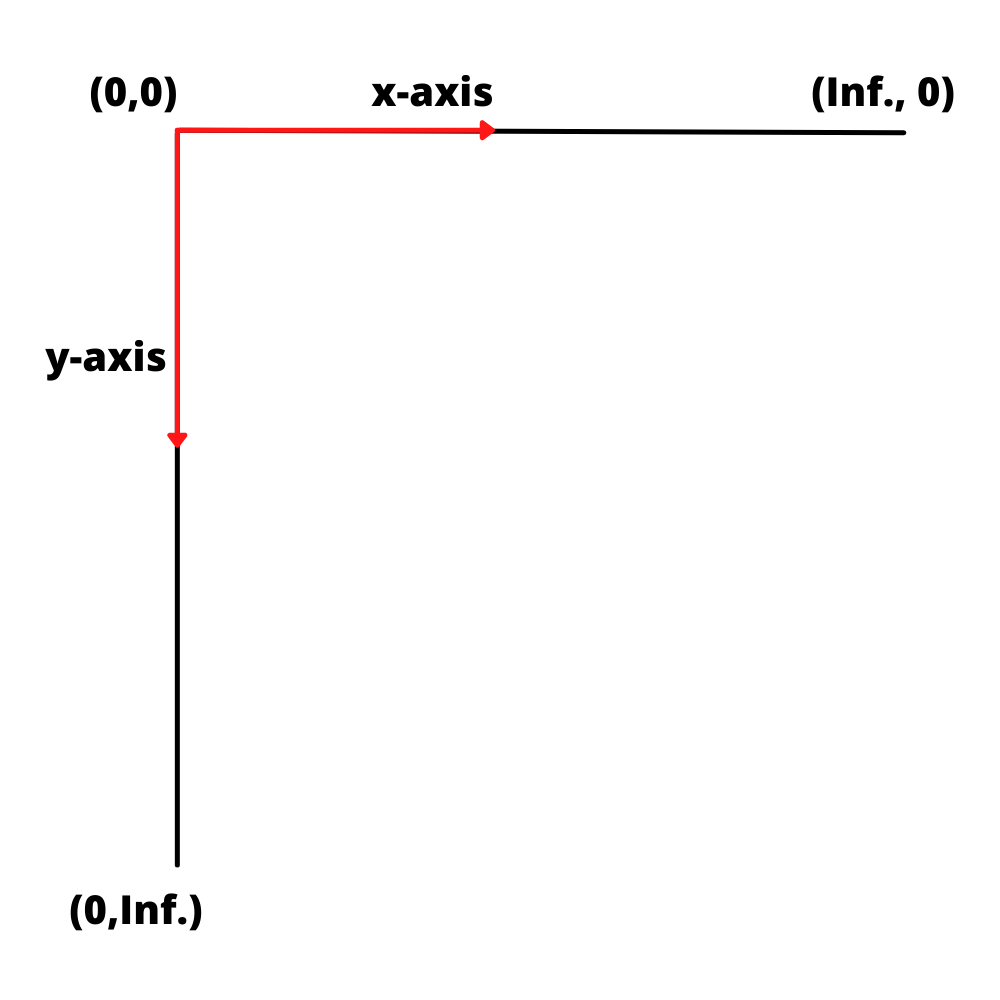

Each box around the text is a bounding box. The job of the bounding box is to identify the location coordinates of each piece of text. The location of each bounding box is denoted using x and y coordinates (according to the x and y coordinate system visualized above).
The coordinates are passed through embedding layers to codify them for the model. Using one embedding for text and four position embeddings, the final embedding for each piece of text on the invoice is created and passed on to LayoutLM. In other words, the locational and character information extracted by OCR is the input for LayoutLM.
Image Embedding
If the invoice contains images or pieces of text that cannot be identified as characters, LayoutLM needs the image location and interpretation (or embeddings) as input. For this, an image model like Faster R-CNN is suitable to perform object detection.
The text, location, and image embeddings collected from OCR and Faster R-CNN are together used as the LayoutLM input for downstream tasks.
Further Processing by LayoutLM
LayoutLM has received pre-training on the IIT-CDIP test collection, which has 6 million scanned documents and 11 million scanned document images. It goes one step further. Using Masked Visual Language Modeling, it has learned to determine what text may be present in a document based on the image and location information. Moreover, since large datasets often do not contain information about document classes, LayoutLM has also learnt multi-label document classification.
Due to this pre-training, it already does a good job of recognizing and processing invoices. However, LayoutLM may need additional training to understand different invoice formats. For each format, it may need about 200 training images.
For any enterprise that needs to train or fine-tune LayoutLM for its custom use, here are the key things to keep in mind:
OCR bounding boxes can have one or multiple words. But to label the data appropriately, LayoutLM needs each word and its location.
While fine-tuning LayoutLM, it is crucial to define labels for each word. This helps the model perform better sequence labeling and accurately classify each word.
LayoutLM uses the Tesseract open-source library to perform text extraction. However, a more accurate and more extensive database would be better. Consider using Google Cloud Vision or AWS Textract if budget is not a constraint.
While each enterprise can attempt to fine-tune LayoutLM for custom use, one-stop platforms that combine document processing and data intelligence are a better investment.
How LayoutLM Compares Against Other NLP Models
When compared against the state-of-the-art NLP models like BERT and RoBERTa, LayoutLM was found to be better at form understanding, receipt understanding, and document image classification.
For form understanding, the benchmark dataset was the FUNSD dataset, which contains 199 annotated forms and more than 30,000 words.
For receipt understanding, the benchmark was the SROIE dataset, which contains 626 receipts for training. Additionally, it contains 347 receipts for testing.
For document image classification, the benchmark dataset was the RVL-CDIP dataset with 400,000 images.
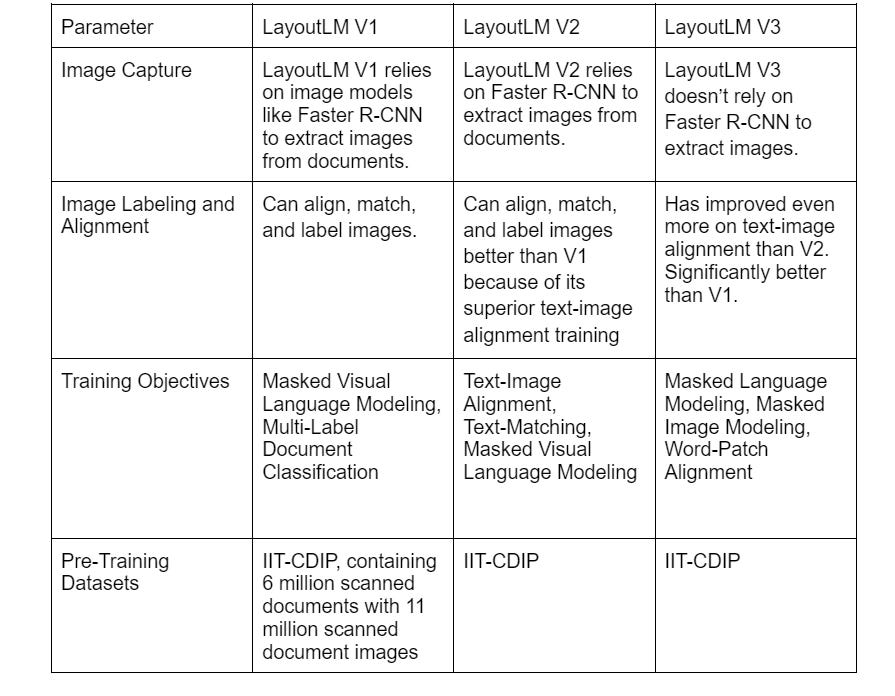
LayoutLM V2 and V3: The Progress Over V1
LayoutLM V2
Released in January 2021, LayoutLM V2’s training objectives were slightly different from that of LayoutLM V1. Here’s how:
Text Image Alignment: LayoutLM V2 can combine both visual and textual information. During the pre-training phase, the V2 version was given images with text covered (i.e., masked) and had to identify whether the text was covered.
Text Image Matching: LayoutLM V2 can understand whether a piece of text corresponds with an image.
Masked Visual Language Modeling: No change from V1.
LayoutLM V3
Released in April 2022, this model was proposed by Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, and Furu Wei.
LayoutLM V3’s training objectives include
Masked Language Modeling
Masked Image Modeling
Word-Patch Alignment
Layout LM V3 has several improvements over V1 and V2:
LayoutLM V3 is the first version that does not rely on image models like Faster R-CNN to extract images. The previous two could align, match, and label images but could not extract them.
LayoutLM V3 is a state-of-the-art IDP model for text and image-centric documents because it has improved on the alignment and text-image matching aspects.
Key Comparisons
LayoutLM V2 and LayoutLM V3 outperform LayoutLM at form understanding, receipt understanding, and document image understanding.
LayoutLM V1 needs to be fine-tuned to include visual embeddings. In the case of LayoutLM V2, these visual embeddings are covered during pre-training.
LayoutLM V3 is primarily identical to V2. However, it needs images in RGB format (instead of BGR used by LayoutLM V1 and V2).
Unlike V1 and V2, which used WordPiece for text tokenization, LayoutLM V3 uses byte-pair encoding.
Final Takeaways
Intelligent Document Processing (IDP) is a faster, cheaper, and more accurate way for businesses to extract, clean, and organize data spread across multiple types of documents. Combined with humans-in-the-loop to handle edge cases, IDP is the best approach to document processing on the market today.
While pre-trained IDP platforms today can handle digital and scanned document images and text using computer vision, LayoutLM is the only one that considers text, image, and layout information simultaneously while processing visually rich documents. Its pre-training techniques are better than state-of-the-art NLP models like BERT and RoBERTa at key document image understanding tasks.
While LayoutLM and its subsequent versions are excellent options for businesses, it is best to use an end-to-end solution that performs both document processing and derives relevant insights from the processed data. Doing so does not require any in-house coding infrastructure or workforce and can be cost-efficient in the long run.
Subscribe to get full access to the newsletter and website. Never miss an update on major trends in AI and startups.
Here is a bit more about my experience in this space and the two books I’ve written on unsupervised learning and natural language processing.
You can also follow me on Twitter.