
The Past, Present, and Future of LLMs
Explore the evolution of LLMs, from their early beginnings to future possibilities in language processing, and secure your place in the new, AI-driven era.


Key Takeaways
The earliest LLMs were based on three simpler neural networks: RNNs, CNNs, and LSTMs. They had several advantages over traditional, rule-based systems but fell short of today’s predominant neural network architecture, called transformers.
LLMs have significantly improved at multiple NLP tasks since the advent of the transformer model in 2017.
The release of more sophisticated language models like GPT-3 in 2020 raised ethical concerns about using sensitive data in training.
Currently, research efforts are looking to reduce computational demand to make large language models more accessible.
Future LLM development aims to create more efficient models with improved reasoning and context understanding abilities without breaking ethical guidelines.
Multimodal LLM development is also a big part of future research, as these models can process different data types like text and images.
Technical advancements are essential for LLM advancement, but ethical issues should also be taken more seriously moving forward.

This post is sponsored by Multimodal, an NYC-based startup setting out to make organizations more productive, effective, and competitive using generative AI.
Multimodal builds custom large language models for enterprises, enabling them to process documents instantly, automate manual workflows, and develop breakthrough products and services.
Visit their website for more information about transformative business AI.
Introduction
Large language models (LLMs) have pushed the boundaries of natural language processing (NLP) capabilities in the past decade, expanding the potential of how machines can use and process human language.
This includes many complex yet highly practical applications, such as code generation, content creation, and language translation.
Some of the world’s biggest organizations, including Meta, Google, and Microsoft, have shifted their focus toward LLM development, while specialized LLM providers are constantly improving their models and getting shockingly better results each year.
But how did we get to this point? Let’s explore the history of LLM development, the current state of LLMs, and where we could be heading in the future.
Past: The Birth of LLMs
It all began with advancements in neural networks and various deep learning techniques because of increased computational power and data availability.
The earliest LLMs were based on the then SOTA recurrent neural networks (RNNs), long short-term memory networks (LSTMs), and convolutional neural networks (CNNs), which have several key advantages over more traditional, rule-based systems:
RNNs, LSTMs, and CNNs have enhanced memory capabilities compared to rule-based systems, which allows them to memorize more past inputs and generate more accurate outputs.
RNNs, LSTMs, and CNNs can also better interpret human language, thanks to their improved understanding of the position and relationships between words, even when they’re far apart in a data sequence.
These neural networks (NNs) were trained on vast amounts of text data, which let them capture complex language patterns.
With the advent of LLMs came the advent of several key training techniques:
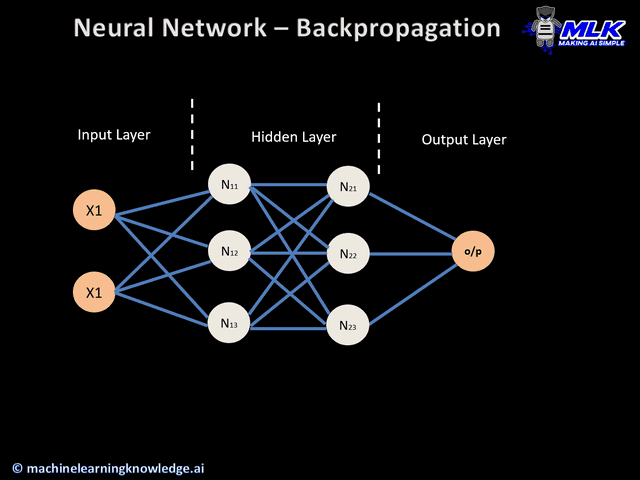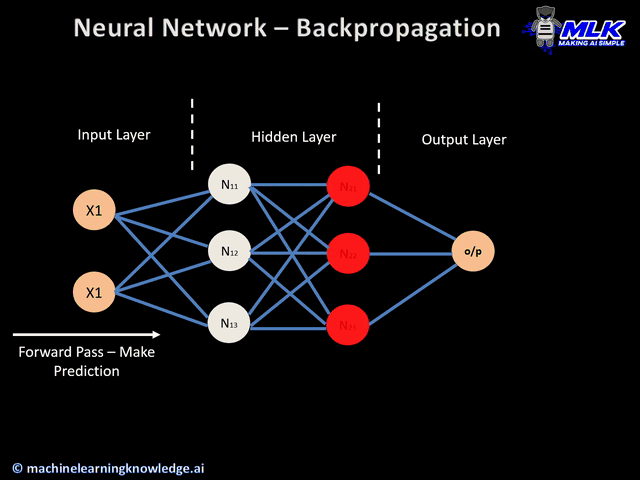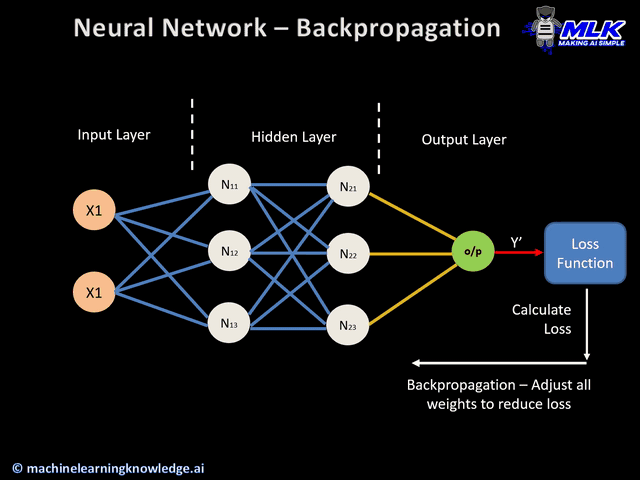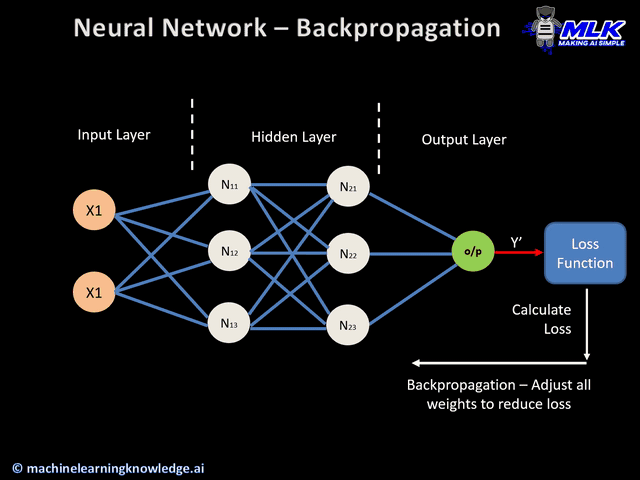
Backpropagation: This is a key technique used in LLM training, where the neural network weights are adjusted based on error rates found in the previous epoch.
Dropout: Dropout is used to prevent overfitting in LLM. It removes a number of output features of the layer during each training stage to improve generalization.
Transfer Learning: The language model is trained on a massive dataset, with fine-tuning then being used to specialize the model in a specific application.

{kind=link}
2017: Transformer
With these advancements in deep learning algorithms came the birth of the transformer model in 2017, introduced with the “Attention is All You Need” paper. It was a pivotal moment in LLM because of its new approach to machine learning models.
As mentioned, the primary neural network architecture used in large language model development included RNNs, LSTMs, and CNNs. However, they were limited in that they weren’t able to process longer data sequences and consider the overall context of the input sequence. Consequently, the outputs of LSTMs and RNNs were prone to inaccuracy.
These limitations, along with other challenges, were overcome with the advent of new neural networks – transformers – and their added layers called attention mechanisms.
Attention mechanisms allow the models to focus on more important aspects of the input by prioritizing and managing the context information. That way, the models don’t have to capture all of the context at once, which increases their accuracy and reduces the associated computational costs compared to earlier NNs.
2018: BERT
These advancements paved the way for one of the first transformer-based models: Google’s Bidirectional Encoder Representations from Transformers (BERT).
In contrast to the previous approach, where language models only examined one direction of a word, BERT examines language context in both directions. As a result, BERT improved at multiple tasks, such as sentiment analysis and answering questions. This set a new standard for LLMs and opened new doors for researchers and developers.
2019: GPT-2
OpenAI introduced generative pre-trained transformer (GPT) models just a year after BERT’s official release. Their GPT-2 model was another big stepping stone in the world of LLMs and marked a key transition from language understanding to language generation. It was built on the transformer architecture but on a much bigger scale, with the model having 1.5 billion parameters.
This larger language model was trained on vast amounts of text and used unsupervised learning to predict the next word in a sentence. This model had remarkable capabilities, including generating human-like text, which meant that GPT-2 surpassed its LLM predecessors.
2020: GPT-3
The pivotal moment happened in 2020, when OpenAI continued its hot streak in LLM advancements by releasing GPT-3, a highly popular large language model. GPT-3 is a pre-trained model that can learn a wide range of language patterns due to the vast quantity of training data used.
With 175 billion parameters, GPT-3 was even better than GPT-2 at producing human-like text and understanding human language.
The University of Toronto compared the performance between the two GPT models on various tasks. One test compared the performance on sentiment analysis, where GPT-3 achieved an accuracy of 92.7% and GPT-2 scored an accuracy of 88.9%.
GPT-3 was a huge milestone that led many to realize the potential and versatility of language models.

While the release of the GPT models marked massive milestones in language model development, they also brought new challenges to light.
The capacity of LLMs to generate plausible but false information raises alarms as this information can be misused. The autonomous nature of these models also creates questions about who should be held accountable when the model produces harmful or unethical outputs.
Additionally, these large language models were mainly trained on unvetted internet data, which often contains inappropriate, harmful, or biased content. This led to the models obtaining biases, reflecting them in their outputs, and often promoting negative societal views.
Nevertheless, developers and organizations continued to explore the potential of language models, which led us to where we are today.
Present: Current Challenges
As the capabilities of large language models expanded, so did the computational demand. Efforts are now being directed toward reducing computational demand to increase the accessibility and efficiency of LLMs.
The training process of GPT-3, for example, involved using hundreds of GPUs to train the model over several months, which took up a lot of energy and computational resources. Only a small number of large organizations could afford such demanding training processes.
Research is directed at making the training process more efficient by using techniques like model distillation, where smaller models are trained to mimic the behavior of larger models.
Another problem is the ”black box” nature of language models. LLMs often lack interpretability, which makes it difficult to understand how they arrive at their conclusions. The models rely on complex neural networks that process and analyze vast amounts of data, leading to difficulty in tracing the reasoning behind their outputs.
This lack of interpretability raises concerns about how much trust we should place in these models, making it difficult to address possible errors in the model’s decision-making process.
When language models are used for situations that require high accuracy, like medical diagnoses, where do we draw the line? Work is being done to shed more light on how language models work so the human user can trust the model’s output more.
The third challenge is how models like GPT-3 use vast quantities of training data, leading to sensitive and private data being used in the training process.

We’ve seen how good language models are at various language tasks, but they still have issues generating predictions in highly specialized fields, such as legal or medical contexts.
Medical records and legal documents, for example, often contain private information, so using them for model training is usually not possible. As a result, many models lack the knowledge specific to these domains and produce lower-accuracy predictions.
Research interest is growing in developing custom agents, which are LLM tools specialized for specific functions. One example used for custom agent software development is LangChain, a framework for creating applications with specific use-cases using LLMs. It aims to simplify the application creation process.
Language models have changed a lot since 2017, but where is the field of LLM development headed in the future?
Future: Where do we go next?
The future of LLMs has a few areas of research and development that stand out. We talked about how efficiency is a big focus. That doesn’t mean just creating bigger models, but also smarter ones.
The goal is to train the models to handle various natural language tasks they didn’t encounter during training. We might see the ability of language models to generalize improve in the future.
Currently, LLMs have big limitations regarding reasoning and contextual understanding abilities. While they’re great at generating human text, they aren’t great at understanding the output they give. One avenue of improvement for future language models is to refine their capabilities based on human feedback.
Ethical considerations have increased as LLM capabilities have improved. Future LLM development is likely to reconsider the usage of sensitive data for training and provide more transparency in how outputs are generated.
New research explores how to train models with smaller but targeted datasets instead of bigger datasets that might use sensitive data.
One possible approach is to train a model with a larger, less sensitive dataset containing a lot of text to allow the model to gain a broad understanding of language. It can then be fine-tuned with a smaller, more specific dataset to allow the model to specialize in a specific use-case and reduce its exposure to sensitive data.
Multimodal LLMs
Many current language models are text-based, but we could see models simultaneously handling text, images, and audio data. These are called multimodal LLMs, which have a range of applications, such as generating image captions and providing medical diagnoses from patient reports.

Edge Device LLMs
LLMs continue to evolve and are moving towards a more efficient solution called edge device LLMs.
These models are optimized to run on local devices instead of remote servers. Typically, these models are trained on smaller datasets to meet the constraints of edge device GPUs like phones. Edge device LLMs help with data privacy as data processing is kept local.
While more advanced LLMs like the newer GPT models are too resource-intensive for edge device GPUs, research looks into model compression and optimization while maintaining their capabilities.
LLM development was mostly about technical advancements previously. While these are great, we’ve also learned the importance of not overlooking ethical considerations.
Looking ahead
LLMs have come a long way, with transformer models paving the way and popular LLMs like GPT-3 drastically increasing public awareness of language models.
With all the advancements in language tasks, the old saying is more relevant than ever when it comes to artificial intelligence and ethical guidelines:
“With great power comes great responsibility.”
The misuse of private data and autonomous decision-making is a big focus moving forward when developing new LLMs. The technical capabilities of LLMs will improve with multimodal models, and they’ll do so more efficiently and ethically.
Language models have led to unprecedented opportunities, and many more doors are likely yet to open.
One thing is for sure: it’s an exciting time to be a part of.