
The LLM Journey: From OpenAI Innovations to Open-Source Frontiers
Explore the evolution of OpenAI’s GPT models, the rise of open-source alternatives, and what the future holds for LLM development.


Key Takeaways
OpenAI, with its GPT models, has led AI research and significantly influenced LLM development.
From GPT-1’s innovative approach in 2018 to GPT-4’s multimodal capabilities in 2023, each model has resulted in significant advancements in NLP.
Open-source LLMs like LLaMA-2 and the Falcon models are strong competitors to proprietary models.
Falcon-180B was released in September 2023 and is currently the best-performing open-source model, but it isn’t able to perform as well as GPT-4 in some benchmarks.
Future LLM development could see LLMs with more diverse multimodal capabilities, which include video and sound rather than just text and image inputs.
The LLM space is characterized by a cycle of innovation and holds a future where language models play a more integral role in everyday life.

This post is sponsored by Multimodal, an NYC-based startup setting out to make organizations more productive, effective, and competitive using generative AI.
Multimodal builds custom large language models for enterprises, enabling them to process documents instantly, automate manual workflows, and develop breakthrough products and services.
Visit their website for more information about transformative business AI.
Introduction
Large language models (LLMs) have revolutionized natural language processing (NLP). Before ChatGPT’s release in November 2022, LLMs were a potent tool that went under the radar due to their lack of public accessibility.
When OpenAI finally made ChatGPT accessible to anyone, it quickly gained widespread attention, reaching 1 million users in just 5 days.
This post will trace the development of the GPT models, explore the challenges faced, delve into the rise of open-source competitors, and predict the future trajectory of LLMs.
OpenAI’s Contribution to LLMs
OpenAI was founded in December 2015 and has led the charge in artificial intelligence (AI) research. Their mission is to build safe AI models with practical uses in everyday life. They also work to minimize conflicts of interest that could compromise the broader benefits of AI.
Their most notable contribution to the world of LLMs is the generative pre-trained transformer (GPT) models.
GPT-1
Released in June 2018, GPT-1 was the first GPT model that OpenAI developed, containing 117M parameters. GPT-1 was a significant advancement in NLP by using unsupervised learning.
At the time, GPT-1 outperformed other methods using its innovative approach of a fine-tuned transformer language model.
GPT-1 used two key ideas:
Training a transformer model on large quantities of data with unsupervised learning.
Fine-tuning the model on smaller, supervised datasets to improve the model’s performance at certain tasks.

In doing so, GPT-1 achieved state-of-the-art results in various language tasks. However, GPT-1 required significant computational resources to carry out pre-training. Moreover, the model’s understanding of text was limited to the data it was trained on. This resulted in the model having a limited and inaccurate understanding of various subjects.
GPT-2
OpenAI then developed GPT-1’s successor: GPT-2. This model contained 1.5B parameters and is also a transformer-based model. It was trained to predict the next word in 40GB of internet text, which was used to ensure the model was trained on a diverse dataset.
The main training objective of GPT-2 was to predict the next word based on the previous words in a text. Consequently, the model showed that it could perform well at various tasks in different domains, which was something that GPT-1 struggled with.
In essence, GPT-2 is a scaled-up version of GPT-1, having 10 times the number of parameters and using a dataset that is 10 times bigger.
A key improvement over the previous GPT model was GPT-2’s ability to generate human-like text when given an initial input. The use of a diverse dataset meant that GPT-2 could carry out various language tasks, like question answering and summarization. It could also perform well at more domain-specific tasks without using any specific training data from these domains.
GPT-2 also had its own set of limitations. One of which includes GPT-2 producing repetitive text, meaning that its outputs weren’t always concise and coherent. Due to its training on internet data, the language model was biased. These biases were sometimes reflected in the model’s outputs.
OpenAI was concerned that GPT-2 would be misused, so they initially withheld the full model from public release. Instead, they released smaller models first to determine what risks the model presented when in public hands. Eventually, they released the full model when they decided it was safe enough to do so.
GPT-3
In 2020, OpenAI released its most popular model, GPT-3. What sets GPT-3 apart from its predecessors is the integration of attention mechanisms. This lets the model focus on the most important sections of text that it thinks are the most relevant.
GPT-3 was a big step up from GPT-2 because of its massive increase in parameters. While GPT-2 contained 1.5B parameters, GPT-3 contained a massive 175B parameters.

Moreover, GPT-3 was trained on billions of words using the CommonCrawl dataset. Its extensive training dataset meant that GPT-3 could perform well at numerous tasks, ranging from programming in different programming languages to carrying out arithmetic.
GPT-3’s ability to generate human-like text was significantly improved over previous GPT models. An experiment was carried out where participants attempted to determine if short articles were written by a human or generated by GPT-3. The participants correctly identified if the text was human or AI 52% of the time.
Although the model’s text wasn’t completely indistinguishable from human text just yet, it was clear that LLMs were advancing and that the model’s text would become extremely similar to human text in the future.
GPT-4
After the highly successful GPT-3, OpenAI released their latest GPT model in March 2023 called GPT-4.
As with its predecessors, GPT-4 uses a transformer-based architecture. Regarding training data, GPT-4 is trained using public data and data licensed from third-party providers. After the initial training phase, GPT-4 underwent fine-tuning and reinforcement learning from both humans and AI, which helped ensure the model’s outputs aligned with human values.
OpenAI didn’t disclose the technical details of GPT-4’s training process, but they did mention the training process costs were over $100M.
GPT-4 is more reliable and creative than its predecessor because it can handle more specific instructions and understand a larger variety of contexts.
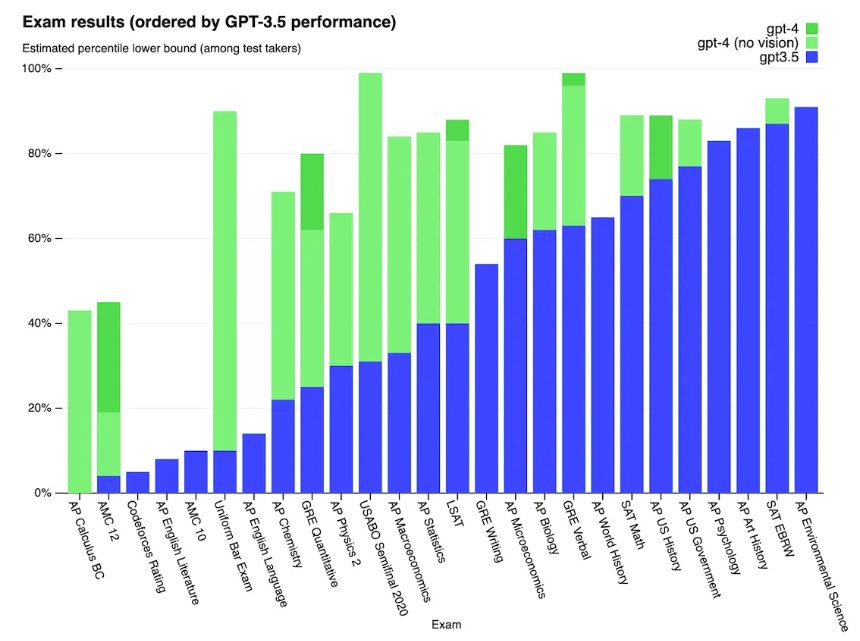
Notably, GPT-4 excels at coding tasks, including the identification of errors in existing code along with suggestions on new code to write next. This makes GPT-4 a valuable asset in software development since it makes the coding process more efficient.
Another big improvement over previous models is that GPT-4 can understand and generate content across various types of data, aside from text. In particular, GPT-4 can take images as input and produce text output about them.
Even though GPT-4 is a state-of-the-art, high-performance language model with versatile applications, it still has limitations. One issue is the need for transparency. It isn’t clear how the model came to any of its conclusions, making it difficult for humans to trust its outputs fully.
Other Advancements and Breakthroughs
Aside from the GPT models, OpenAI has been paramount to the success of LLM development in other areas.
One of which is AI safety research, as the dangers of AI and LLMs are well-known. They’ve taken care to ensure that ChatGPT doesn’t produce harmful outputs, even if the model is given prompts that encourage them to produce harmful outputs. This means OpenAI wants to ensure its models provide highly valuable and applicable outputs that align with human values.
Another area of LLM development in which OpenAI has been a significant contributor is zero-shot and one-shot learning. This means the model can carry out tasks it hasn’t seen before, making it highly versatile by performing well at a variety of language tasks.

Moreover, OpenAI has carried out research into various fine-tuning techniques. Although the base model is trained on vast quantities of training data, it can be fine-tuned with more specific training data to adapt it to more focused applications.
One technique includes transfer learning, which involves applying pre-training knowledge to a new task. This lets the model quickly adapt to new situations by using data and knowledge from the pre-training process.
Despite the outstanding accomplishments and advancements that OpenAI has led in LLM development, there are still various issues in the field of LLMs.
Challenges of LLMs
We saw earlier how OpenAI’s GPT models became more advanced as the models progressed. On the surface, it could seem like this progression is highly beneficial without any drawbacks. While the advancements have been highly beneficial to people and businesses in various domains, they come with major issues.
The advancements of LLMs mean they can replace humans in certain tasks, which results in job displacement. Examples include customer support, data entry, and content creation.
Furthermore, the large datasets used to train LLMs often contain biased information. This results in the model reflecting these biases in its outputs, resulting in discriminatory or unfair outputs.
It’s also possible that the dataset used to train the LLM contains personal information, which could also be reflected in the model’s outputs. As a result, this leads to privacy concerns and potentially even legal issues.
Another issue is that LLMs can “hallucinate”, where the model generates factually incorrect information due to overgeneralizing the contexts it encountered during the training process. This can lead to issues like false information spreading, although it appears deceptively correct at first glance due to the model’s confident outputs.

The lack of transparency has been widely regarded as a key issue with closed-source LLMs, like the GPT models, since the source code isn’t publicly available due to proprietary licenses. Open-source LLMs have emerged as a viable alternative.
The Transition: Why Open-Source?
As LLMs become more integrated into everyday life, building trust in their outputs becomes crucial. Transparency in model development, training data, and methodologies is vital to building this trust.
Open-source models allow developers and users to gain insight into the inner workings of LLMs. These models provide open-source licenses that let developers access the source code and weights of the models. One benefit of open-source code is that developers can freely adjust and change it.
Open-source projects encourage developers and researchers to collaborate, leading to quicker advancements in LLM development.
Moreover, open-source LLMs encourage developers to further discuss the ethical implications and potential biases of AI models. By having a wider range of perspectives, it will become easier to discover solutions to these pressing issues.
Open-Source LLMs: A New Era
Open-source LLMs promise transparency, community-driven improvements, and broader accessibility. Two open-source LLMs that stand out include LLaMA-2 and the Falcon models.
LLaMA-2
Meta released their first LLaMA model in February 2023, but it was only available through a non-commercial license. This led to 100,000 requests for access to LLaMA-1, so Meta decided to release a newer model called LLaMA-2. This model is an open-source project that is available for the public to access under an open-source license.
We mentioned the importance of AI safety earlier, which is also a key focus for OpenAI. Meta has been particularly diligent in what information is used in their training dataset, removing any biased or personal information.
This can be seen in the other LLaMA-2 model called LLaMA-2-chats, specifically developed for chatbot applications.

The approach taken by Meta resulted in LLaMA-2-chat achieving the lowest violation scores out of any LLM so far, which means this language model is the current leader for safe LLM outputs.
LLaMA-2 is also proficient at various NLP tasks like customer service automation and content generation, making it a versatile model that can be used for various applications.
Falcon
In June 2023, Technology Institute Innovate (TII) released two base Falcon models: Falcon-7B and Falcon-40B. Falcon-7B is a model specifically designed for chatbot applications, while Falcon-40B is a more versatile model that can carry out various NLP tasks.
TII was especially cautious with the training data they used for their models, as higher-quality training data will lead to more accurate outputs. They used the RefinedWeb dataset and filtered it to improve training data quality further. As a result, the Falcon models are less likely to hallucinate and produce incorrect outputs.
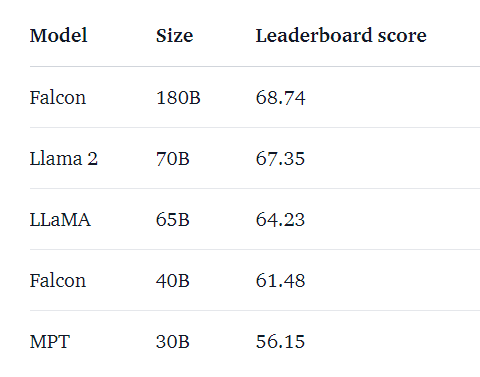
In September 2023, TII released a much larger model called Falcon-180B. This model can outperform GPT-3.5, but doesn’t quite reach the same level as GPT-4 yet in certain benchmarks.
Regardless, Falcon-180B is the best-performing open-source LLM available currently and is a strong contender to overtake GPT-4 with more fine-tuning from the open-source community.
Future Prospects: Beyond OpenAI and Open-Source
Open-source models show promise in how LLM development is advancing, but what does the future hold?
One area of interest is the creation of more efficient models. This avenue will look at creating models that still perform well but are smaller in size. One example is the Falcon-40B model, which outperformed GPT-3 despite having 75% of the training compute budget. In the future, we could see more models follow this trend.
As seen earlier, GPT-4 boasts multimodal capabilities, processing both image and text inputs. Future models are likely to build upon this foundation by being able to process other types of data, like video and sounds.
It’s also likely that future research into LLM development will look into ethical safety. Open-source LLMs like LLaMA-2 are already achieving low violation scores, so it’s logical that future LLM development will take safety and ethical issues into consideration.
Another possibility is the development of more specialized LLMs. Models like GPT-4 act as a one-size-fits-all solution by being able to perform various tasks. We could see more fine-tuned models tailored for highly niche applications and use cases instead.
The Cycle of Innovation
With the advent of the GPT models, OpenAI has paved the way for LLM development.
The GPT models became more advanced with each iteration, with the latest model GPT-4 being able to text that is almost indistinguishable from human text and perform well at tasks that require advanced reasoning skills.
However, the emergence of open-source models has meant that developers can collaborate and push the boundaries of LLM development further.
This ongoing cycle of innovation forecasts a future where LLMs are further integrated into our lives, reshaping industries and enhancing productivity.