
Pinecone vs. Weaviate vs. Milvus for Vector Search
Compare Pinecone, Weaviate, and Milvus—leading vector databases for AI applications. Explore their strengths in vector search, scalability, and deployment.


Key Takeaways
Vector databases like Pinecone, Weaviate, and Milvus play a pivotal role in AI applications by efficiently handling high-dimensional vector embeddings for tasks such as semantic search, recommendation systems, and generative AI.
Pinecone excels in real-time vector similarity searches with minimal setup and low-latency performance, making it ideal for applications requiring fast query responses and cloud-native infrastructure.
Weaviate's hybrid search capabilities and support for multi-modal data bridge the gap between structured and unstructured data, providing flexibility for projects involving semantic meaning and complex queries.
Milvus stands out for its scalability and modular architecture, enabling efficient similarity searches across massive datasets and diverse indexing methods tailored to specific project requirements.
Choosing the right vector database depends on deployment preferences, scalability needs, query complexity, and cost considerations, with Pinecone suited for ease of use, Weaviate for hybrid search, and Milvus for large-scale AI workloads.

In 2023, I started Multimodal, a Generative AI company that helps organizations automate complex, knowledge-based workflows using AI Agents. Check it out here.
Vector databases play a pivotal role in modern AI applications, enabling efficient handling of high-dimensional vector embeddings generated by machine learning models. Unlike traditional relational databases, they excel in managing vast amounts of unstructured data, supporting semantic search, recommendation systems, and generative AI tasks. Pinecone, Weaviate, and Milvus are leading solutions in this space, each offering unique capabilities for vector similarity searches and complex queries.
Let’s explore their strengths in handling structured and unstructured data, scalability for massive datasets, and deployment options to help developers choose the ideal vector database for specific project requirements.
Overview of Each Database
Pinecone
Pinecone is a fully managed, cloud-native vector database designed to simplify vector search and deliver real-time processing for high-dimensional vectors. It excels in handling vast amounts of vector data with minimal setup, making it a go-to choice for AI applications requiring low-latency performance and seamless scalability.
Key Features
Cloud-native infrastructure: Eliminates the complexity of infrastructure management, allowing users to focus on generating embeddings and retrieving relevant results.
Real-time processing: Optimized for vector similarity searches with sub-2ms latency, even for massive datasets.
Straightforward API: Simplifies integration into machine learning workflows, supporting both dense embeddings and sparse embeddings.
Common Use Cases
Recommendation Systems: Leverages semantic similarity to deliver personalized suggestions in e-commerce or content platforms.
Retrieval-Augmented Generation (RAG): Enhances generative AI by retrieving contextually relevant data for large language models.
Semantic Search Applications: Enables complex queries by understanding semantic meaning, ideal for knowledge base retrieval or question answering.
Strengths
Exceptional performance metrics for nearest neighbor searches.
Supports high throughput workloads with minimal compute resource overhead.
Limitations
Proprietary platform limits flexibility compared to open-source alternatives.
Deployment options are restricted to cloud environments.
Weaviate
Weaviate is an open-source vector database that combines hybrid search capabilities with multi-modal data support. It bridges the gap between structured data and unstructured data, enabling semantic search across diverse data types like text embeddings and images.
Key Features
Hybrid Search: Combines vector similarity searches with scalar filtering to handle both structured and unstructured queries effectively.
GraphQL API: Offers a user-friendly query interface for managing metadata and performing complex queries.
Multi-modal Support: Handles diverse data types, including images and text embeddings, making it versatile for AI applications.
Common Use Cases
Semantic Search Applications: Ideal for retrieving semantically similar results in domains like natural language processing or generative AI.
Multi-modal Data Applications: Supports combining text, images, and metadata for tasks like image classification or cross-modal retrieval.
Knowledge Base Retrieval: Enables precise question answering by indexing vast amounts of structured and unstructured data.
Strengths
Open-source flexibility allows users to self-host or deploy on the cloud based on specific project requirements.
Strong support for hybrid search enables complex queries across metadata-rich datasets.
Limitations
Slightly higher latency compared to Pinecone in real-time scenarios.
Requires more manual configuration for index creation and performance tuning.
Milvus
Milvus is an open-source vector database purpose-built for large-scale AI applications. Its modular architecture supports diverse index types, making it highly adaptable to various machine learning applications requiring efficient similarity searches.
Key Features
Scalability: Designed to handle trillions of high-dimensional vectors, making it suitable for massive datasets.
Diverse Index Types: Supports HNSW, IVF, and other indexing methods to optimize nearest neighbor searches based on specific use cases.
Flexible Deployment Options: Offers both self-hosted and cloud-native setups to meet varying infrastructure needs.
Common Use Cases
Embeddings Management: Handles dense embeddings generated by machine learning models for tasks like semantic similarity or recommendation systems.
Similarity Search at Scale: Powers large-scale AI applications like image retrieval or anomaly detection in IoT sensor data.
AI Applications in Research: Supports compute-intensive tasks such as drug discovery or climate modeling through efficient vector search.
Strengths
Exceptional scalability makes it a top choice for organizations managing vast amounts of vector data.
Modular design allows customization of index creation and query optimization based on performance metrics.
Limitations
Steeper learning curve compared to Pinecone and Weaviate due to its modular architecture.
Requires expertise in infrastructure management to achieve optimal performance.
Comparison Summary
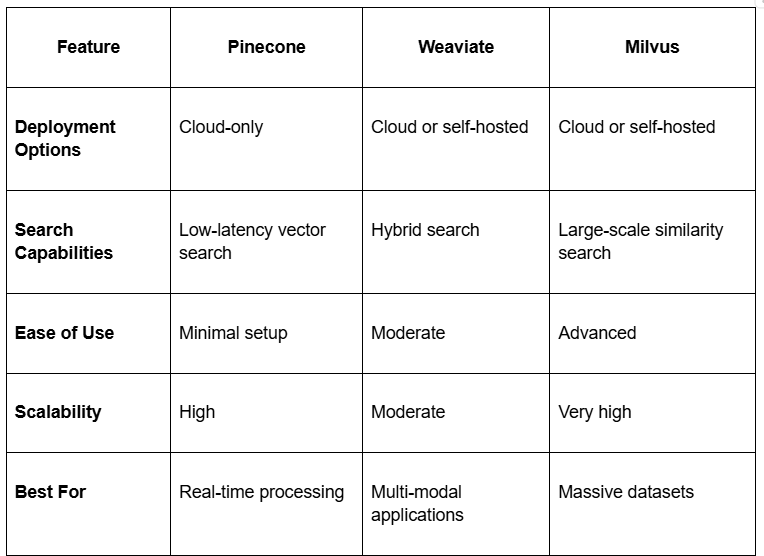
Each database offers unique strengths tailored to specific project requirements. Pinecone is ideal for real-time processing with minimal setup; Weaviate excels in hybrid search across multi-modal data; Milvus is unmatched in scalability for handling massive datasets.
Strengths and Weaknesses
Pinecone
Strengths
Fully managed service eliminates operational overhead.
Exceptional performance for real-time applications.
Simple integration with machine learning workflows.
Weaknesses
Proprietary licensing limits customizability.
Higher costs for large-scale deployments compared to open-source options.
Weaviate
Strengths
Open-source flexibility with strong hybrid search capabilities.
Built-in support for multi-modal data and customizable models.
GraphQL API simplifies querying.
Weaknesses
Limited transaction support (eventual consistency in distributed setups.
Slightly higher latency compared to Pinecone and Milvus.
Milvus
Strengths
Highly flexible with diverse indexing options tailored to specific needs.
Scalable architecture supports massive datasets (trillion-scale vectors).
Strong community support and open-source ecosystem.
Weaknesses
Requires manual configuration for optimal performance.
Learning curve can be steeper due to its modular design.
Performance Benchmarks
Latency and Recall Rates
Pinecone excels in low-latency scenarios (<2ms) with high recall rates.
Milvus offers competitive recall but may require tuning to minimize latency.
Weaviate performs well (<100ms) but is slightly slower than Pinecone and Milvus for massive datasets.
Use Case Suitability
When to Choose Pinecone
Real-time applications requiring ultra-low latency (e.g., recommendation systems).
Teams prioritizing ease of use over customizability.
When to Choose Weaviate
Projects needing hybrid search across structured and unstructured data.
Teams preferring open-source solutions with multi-modal capabilities.
When to Choose Milvus
Large-scale AI applications managing trillions of vectors.
Developers needing flexibility in indexing and deployment configurations.
Cost Considerations
Pinecone
Premium pricing model; suitable for enterprise-grade projects requiring managed services.
Weaviate
The open-source option reduces costs but may require investment in infrastructure if self-hosted.
Milvus
Cost-effective for large-scale deployments due to its open-source nature but requires operational expertise.

I also host an AI podcast and content series called “Pioneers.” This series takes you on an enthralling journey into the minds of AI visionaries, founders, and CEOs who are at the forefront of innovation through AI in their organizations.
To learn more, please visit Pioneers on Beehiiv.
Wrapping Up
Vector databases like Pinecone, Weaviate, and Milvus have become indispensable for AI applications, offering powerful solutions for managing high-dimensional vector data. Each database brings unique strengths to the table, catering to different use cases and project requirements.
Pinecone stands out as a fully managed, cloud-native vector database designed for real-time processing. Its low-latency performance and minimal setup make it ideal for recommendation systems, semantic search applications, and retrieval-augmented generation (RAG). However, its proprietary nature and cloud-only deployment may limit flexibility for some users.
Weaviate shines with its hybrid search capabilities, combining vector similarity searches with structured filtering. Its open-source flexibility and multi-modal data support make it perfect for projects involving both structured and unstructured data, such as knowledge base retrieval or multi-modal applications. While versatile, it may require more manual configuration and has slightly higher latency compared to Pinecone.
Milvus is the go-to choice for large-scale AI applications requiring scalability and customization. Its modular architecture supports diverse indexing methods, making it highly adaptable for massive datasets and compute-intensive tasks like embeddings management or similarity search at scale. However, its steep learning curve and need for operational expertise may pose challenges for some teams.
Ultimately, the choice between Pinecone, Weaviate, and Milvus depends on your specific project requirements. Consider factors like deployment preferences (cloud vs. self-hosted), query complexity, scalability needs, and budget constraints. For real-time performance with minimal overhead, Pinecone is a strong contender. For open-source flexibility and hybrid search capabilities, Weaviate is an excellent option. And for handling massive datasets with advanced indexing options, Milvus is unmatched.
By carefully evaluating your use case—whether it's semantic search, recommendation systems, or generative AI—you can select the right vector database to unlock the full potential of your machine learning models.
I’ll come back next week with more insights on building AI for enterprises.
Until then,
Ankur.