
PaLM 2 vs. GPT-4 vs. Claude 2 vs. Code LLaMA - Which Model Wins the LLM Race?
In this article, we will compare four foundational models: GPT-4, PaLM 2, Claude 2, and Code LLaMA. Discover which model suits your needs the best.


Key Takeaways
The past year has witnessed unprecedented growth in the LLM field. New models offer innovative applications and specialized versions of existing models.
GPT-4 is a versatile LLM with multimodal capabilities, trained on diverse datasets, making it a powerful tool for various NLP tasks.
PaLM 2 showcases improved reasoning abilities, especially in tasks like WinoGrande and DROP, and excels in mathematical challenges.
Claude 2 possesses a unique ability to recognize and respond to emotions in text, making it promising for human-machine interactions, customer service, and mental health support.
Code LLaMA is a specialized model designed for coding tasks, outperforming open-source alternatives in code completion and generation benchmarks.
While costly, legacy models like PaLM 2 and GPT-4 can be effective. At the same time, models like Code LLaMA and Claude 2 can achieve excellent performance at an affordable level.

This post is sponsored by Multimodal, an NYC-based startup setting out to make organizations more productive, effective, and competitive using generative AI.
Multimodal builds custom large language models for enterprises, enabling them to process documents instantly, automate manual workflows, and develop breakthrough products and services.
Visit their website for more information about transformative business AI.
LLMs have been around for a long time now. But the traction in the LLM field has been mind-blowing in the past year. Companies are coming up with innovative applications and fine-tuned versions of existing models, and a new AI language model is released every week.
Recently, OpenAI released GPT-4. To compete, Google released PaLM 2 and Anthropic came up with Claude-2. Around the same time, Meta added Code LLaMA to its series of open-source LLMs. With this race speeding up, it’s difficult for businesses and consumers to choose one model for building applications.
While their utilities are different and specific, a side-by-side comparison of all these models is essential for decision-making.
We’ll look at four foundational models: GPT-4, PaLM 2, Claude 2, and Code LLaMA.
Claude-2 Vs GPT-4 Vs PaLM 2 vs Code LLaMA
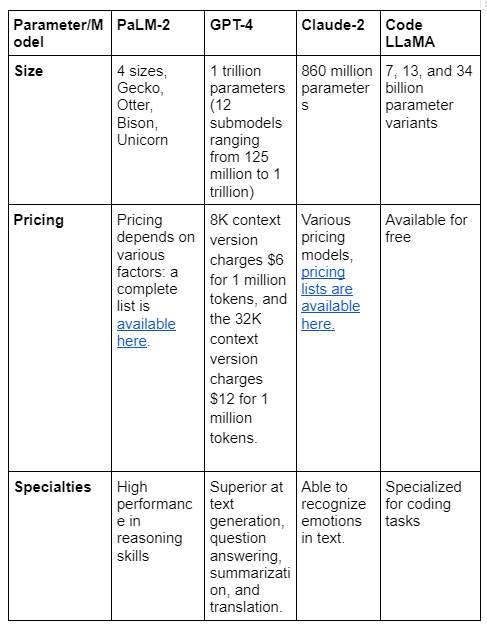
Currently, GPT-4 and PaLM 2 are state-of-the-art large language models (LLMs), arguably two of the most advanced language models.
Anthropic’s Claude 2 is a potential rival to GPT-4, but of the two AI models, GPT-4 and PaLM 2 seem to perform better on some benchmarks than Claude 2. Code LLaMA is specific to coding and is a fine-tuned version of Meta’s LLaMA 2, with its coding capabilities enhanced.
Here are some comparisons between these multiple models:
A. Basic Introduction
First, we’ll look at a general overview of each model.
What is GPT-4?
The newest in the series of Generative Pre-Training models developed by OpenAI, GPT-4 is a foundational language model. With some of the earlier LLMs developed by OpenAI being text-only language models, GPT-4 is a refresher because of its multimodal nature. It has been trained on a vast and diverse dataset compared to previous GPT versions.
What is PaLM 2?
Google announced PaLM 2 at the I/O 2023 conference. Since its release, the model has been used to power Bard AI, Google’s rival to ChatGPT. This is another large multimodal model demonstrating human-level performance. Its dataset and training are incredibly superior to PaLM, and AI experts speculate that it might soon become the go-to for LLM developers.
What is Claude 2?
Anthropic has developed this text and code-only language model to rival the performances of PaLM 2 and GPT-4. While it isn’t multimodal like the other two, it can be used to process vast amounts of data at once because it allows inputs of up to 100K tokens.
What is Code LLaMA?
Meta developed two open-source LLMs earlier this year: LLaMA and LLaMA 2. Code LLaMA is built on top of LLaMA 2. The existing dataset of LLaMA has been refined, and it has been explicitly trained on coding tasks.
B. Model Capabilities
The models each have their own specialty in terms of what tasks they perform well at.
GPT-4
GPT-4 can perform a versatile range of natural language processing (NLP) tasks: text generation, question answering, summarization, translation, and code generation. It can generate a human-like output of up to 25,000 words and even take image inputs.
This AI model has superior text training, so it excels even when it comes to creative writing. According to the GPT-4 research paper:
"The data is a web-scale corpus of data including correct and incorrect solutions to math problems, weak and strong reasoning, self-contradictory and consistent statements, and representing a great variety of ideologies and ideas."
GPT-4 utilizes reinforcement learning to improve its results, especially when it comes to question-answering tasks. This way, the model has been fine-tuned to learn from human feedback. While the model can be used for coding, it is best for text-based tasks.
PaLM 2
Google claims PaLM 2 exhibits improved reasoning abilities compared to GPT-4 in various benchmarks. These improvements are particularly evident in tasks like WinoGrande and DROP, where PaLM 2 outperforms GPT-4 by a small margin. However, when we look at ARC-C, although PaLM 2 shows some progress, it is not as substantial as in other benchmarks.
In addition to reasoning, PaLM 2 also demonstrates enhanced mathematical capabilities, as detailed in Google's extensive 91-page research paper on PaLM 2. It's worth noting, that comparing PaLM 2 directly with GPT-4 can be challenging due to the different ways in which Google and OpenAI present their test results.
Google has specific certain comparisons, possibly because PaLM 2 did not perform as well as GPT-4 in some instances.
For instance, in the MMLU benchmark, GPT-4 scored 86.4, whereas PaLM 2 scored slightly lower at 81.2. A similar trend is observed in HellaSwag, where GPT-4 attained a score of 95.3, while PaLM 2 managed 86.8. Lastly, in the ARC-E benchmark, GPT-4 and PaLM 2 obtained scores of 96.3 and 89.7, respectively.
These results highlight the nuanced differences in performance between the two models across various evaluation tasks.
Claude 2
Claude-2 has the remarkable ability to grasp and replicate human emotions, promising a significant shift in human-machine interactions and how we engage with AI systems. With a capacity to process up to 100,000 tokens, equivalent to around 75,000 words in a given prompt, Claude-2 stands out as highly effective.
What sets Claude-2 apart is its emotional intelligence, which forms the core of its exceptional capabilities. The model can identify emotions conveyed in text, allowing it to gauge the user's emotional state during conversations.
Claude-2 can emulate empathy, compassion, and sensitivity akin to a human conversation partner by comprehending emotions. It doesn't just analyze the words used but also the overall emotional tone and mood of the interaction.
As a result, it can adapt its vocabulary and tone accordingly, ensuring that its responses align with the user's emotional state and facilitating more meaningful and personalized dialogues.
The model can be a virtual companion for individuals dealing with stress, anxiety, and emotional challenges. Its empathetic communication skills have the potential to revolutionize the customer service sector as well.
By understanding and responding to customer emotions, Claude-2 can address concerns with empathy and compassion, ultimately improving customer loyalty and satisfaction, fostering more positive and fulfilling relationships.
Code LLaMA
Drawing a direct comparison between Code LLaMA and the other models above isn’t fair because Code LLaMA is fine-tuned for coding. However, we will compare its coding performance to other models, using the original research paper’s information.
HumanEval assesses the model's proficiency in code completion based on docstrings, while MBPP evaluates the model's ability to generate code based on a provided description.
Benchmark testing revealed that Code Llama surpassed open-source, code-specific Language Model (LLM) alternatives and outperformed its predecessor, Llama 2.
For instance, in the HumanEval benchmark, Code Llama 34B achieved an impressive score of 53.7%, and in the MBPP benchmark, it secured a score of 56.2%. These scores are not only the highest among state-of-the-art open solutions but also place them on par with ChatGPT’s performance.
GPT-4 performed better on the HumanEval benchmark, and there’s a possibility that PaLM 2 might be better too.
C. Other Capabilities
It’s also important to consider what other tasks the models can perform.
GPT-4
GPT-4 can handle various tasks you'd typically expect from an AI assistant. You can use it to create email templates for quicker responses, seek help with debugging code, and access current internet data and research to stay updated on events.
PaLM 2
Multilingual Capability: The second iteration of PaLM has undergone extensive training on a diverse range of texts encompassing over 100 languages.
This intensive training has significantly elevated its proficiency in comprehending, generating, and translating intricate text, encompassing everything from idiomatic expressions and poetic verses to riddles. Impressively, PaLM 2 consistently attains "mastery" level scores in advanced language proficiency examinations.
Logical Aptitude: PaLM 2's expansive dataset encompasses scientific research papers and web content containing mathematical expressions. Consequently, PaLM 2 has better logical reasoning, common-sense deduction, and mathematical problem-solving capacities.
Programming Prowess: Distinguished by its pre-training on an extensive corpus of publicly available source code datasets, PaLM 2 excels in popular programming languages such as Python and JavaScript. It can also code in Prolog, Fortran, and Verilog.
Claude 2
The Claude-2 LLM boasts remarkable speed in executing a broad range of text-related tasks, all in response to user directives. For instance, it can swiftly generate blog posts, craft email templates, provide concise summaries, expand upon existing texts, or facilitate translations into more than ten languages.
Claude 2's proficiency in advanced mathematics, reasoning, and coding extends its utility into programming. It empowers users to generate code and enhance existing programming solutions effortlessly. Moreover, its extensive input capabilities make Claude 2 a valuable tool for debugging existing code, ensuring a seamless coding experience.
Code LLaMA
Code LLaMA’s main capabilities lie in coding.
It's been trained on a vast amount of Python code, totaling 100 billion tokens. Python is a widely used language in code generation, particularly in AI. This specialized model is designed to offer even better performance when dealing with Python and PyTorch, which are essential tools in the AI community.
Code Llama - Instruct is another variation of Code Llama that has undergone fine-tuning with a different focus. Instead of general code generation, it's trained to understand and respond to natural language instructions.
This means you can provide it with a command or request in plain language, and it will better comprehend and generate code accordingly. When using Code Llama for code generation, it's recommended to use the Code Llama - Instruct variants, as they have been fine-tuned to produce helpful and safe code responses in natural language.
D. Pricing
Each model has a different pricing structure.
GPT-4
The GPT-4 model offers users two different pricing plans: 8K context and 32K context. The 8K context version charges $6 for 1 million tokens, while the 32K context version charges $12 for 1 million tokens.
PaLM 2
PaLM 2 has a complex pricing model based on various factors. Check out the official prices here.
Claude 2

Code LLaMA
Code LLaMA is open-source and available for free.
E: Training Dataset
We can also consider what training dataset was used in each model and how this helps with specialization for specific tasks
GPT-4
OpenAI has disclosed that the model's training encompassed both publicly accessible data and licensed datasets. The research page for GPT-4 specifies that the training dataset comprises a vast web-scale corpus.
This corpus encompasses a wide spectrum of content, ranging from:
Accurate and erroneous solutions to mathematical problems
Reasoning of varying strength
Self-contradictory and logically consistent statements
Various ideologies and ideas
PaLM 2
Google's emphasis with PaLM 2 was to deepen its grasp of mathematics, logic, reasoning, and scientific principles, but the company hasn’t revealed the dataset. This involved a significant portion of its training data being dedicated to these specific areas.
According to Google's documentation, PaLM 2's pre-training data comes from various sources, such as web content, books, code, mathematical content, and conversational data. This diverse training has led to broad improvements in the model's performance compared to its predecessor, PaLM.
PaLM 2's conversational abilities have also received a substantial boost. It’s been trained in more than 100 languages, enhancing its contextual understanding and translation skills and setting it apart from previous versions.
Claude 2
Claude 2 was trained on a more recent and more aware dataset to avoid biases. It mainly includes open-source data from the web along with some licensed data.
Code LLaMA
Code Llama is an enhanced variant of Llama 2, developed by subjecting Llama 2 to extended training on datasets specifically designed for coding applications. This was focused on extracting a more substantial volume of data from this dataset over an extended training duration.
Conclusion
In the ever-evolving landscape of LLMs, the competition has intensified with the emergence of GPT-4, PaLM 2, Claude 2, and Code LLaMA. These models each offer distinct capabilities and cater to specific needs.
GPT-4 stands out with its multimodal capabilities and extensive text-based functionality. PaLM 2 excels in mathematics and logic, while Claude 2 brings emotional intelligence to the forefront of human-AI interactions. On the other hand, Code LLaMA is a specialist in coding tasks and surpasses its predecessors.
The applicability of each model will depend on your needs. With this comparison, choosing the one that best reflects your goals and helps you get the most out of your applications should become easier.