
Mistral AI’s Mixtral 8x7B: A Deep Dive Into the Open-Weight Large Language Model
Mistral AI's Mixtral 8x7B model is one of the strongest open weight models. Read for a deep dive into its features and a comparative analysis.


Key Takeaways
Mixture of Experts (MoE) Architecture: Mixtral 8x7B's innovative MoE architecture, featuring eight experts with seven billion parameters, enhances computational efficiency by directing input data to specialized neural network components. This design facilitates efficient model training and inference, showcasing Mistral AI's commitment to cutting-edge architecture.
Efficient Processing and Model Size Optimization: With a strategic emphasis on processing efficiency, Mixtral 8x7B utilizes only two experts per token during inference, optimizing speed without compromising performance. Its reduced model size, compared to larger counterparts like GPT-4, at 46.7 billion parameters, highlights Mistral AI's dedication to practical application optimization.
Versatile Applications and Multilingual Support: Mixtral 8x7B excels in diverse applications, including compositional tasks, data analysis, troubleshooting, and programming assistance. Its multilingual proficiency in languages like French, German, Spanish, Italian, and English solidifies its versatility, addressing a wide array of user needs.
Unconventional Development Journey and Fine-Tuning: Mistral AI's unconventional release strategy using torrents calls attention to its contrast with other polished AI release presentations and sparked discussions within the AI community about the role of open-source models. The rapid reverse-engineering by the AI community and subsequent fine-tuning efforts for specific variants showcase the model's adaptability and the collaborative spirit of its development journey.
Future Prospects and Ongoing Optimization: Mistral AI's commitment to ongoing performance optimization positions Mixtral 8x7B as a frontrunner in evolving language models. Anticipated refinements, feature expansions, and adaptive capabilities demonstrate Mistral AI's forward-looking approach, promising continuous advancements in AI technology.

This post is sponsored by Multimodal. Multimodal builds custom GenAI agents to automate your most complex workflows. Here’s the truth: for basic automation tasks, you’re better off just using existing off-the-shelf solutions – they’re cheaper and honestly good enough. But if your workflows require human-level understanding and reasoning, they just don’t work. There’s no one-size-fits-all solution for automating complex knowledge work.
That’s why Multimodal builds AI agents directly on your internal data and customizes them specifically for your exact workflows. Multimodal also deploys their agents directly on your cloud, integrating with the rest of your tech stack. Their goal is simple: eliminate complexity, so you can focus on driving the business forward.

Mistral AI, a $2 Billion French startup founded in 2023 recently made the headlines with its state-of-the-art large language model Mixtral. The model is a refreshing development compared to the existing large players like LLaMA and GPT series, especially because it decentralizes some of the attention that Google, Meta, and Open AI have been getting.
This article unravels Mixtral 8x7B's architecture, development journey, and technical specifications, shedding light on its key features and applications. We also delve into the model's comparative analysis, versatile applications, and future prospects.
Key Features of Mixtral 8x7B
Mistral AI's Mixtral 8x7B model is one of the strongest open-weight models, introducing a range of key features that set it apart from its counterparts. In this section, we delve into the distinctive attributes that define Mixtral 8x7B's architecture, processing efficiency, model size, context capacity, and licensing.
Mixture of Experts (MoE) Architecture
At the core of Mixtral 8x7B lies its innovative Mixture of Experts (MoE) model architecture. This design paradigm involves a gate network directing input data to specialized neural network components known as "experts." In the case of Mixtral 8x7B, there are eight experts, each boasting an impressive seven billion model parameters.
This MoE framework facilitates more efficient and scalable model training and inference. It enables the activation of specific experts tailored to handle different aspects of the input data, contributing to enhanced computational efficiency.
8 Experts with 7 Billion Parameters
The model's nomenclature, "8x7B," succinctly encapsulates its structure — a combination of eight high-quality sparse mixture of experts, each endowed with seven billion parameters. This amalgamation of expertise allows Mixtral 8x7B to perform at a remarkable level, showcasing the prowess derived from a specialized team of experts collaborating within the neural network.
Efficient Processing with 2 Experts per Token
An aspect that truly sets Mixtral 8x7B apart is its emphasis on processing efficiency. While equipped with eight experts, only two experts are utilized per token during inference. Precisely, Mixtral is composed of 46.7B total parameters, but only uses 12.9B per token (2 experts).
This strategic allocation optimizes processing speed without compromising the model's performance. The implementation of a selective expert activation mechanism ensures that computational resources are judiciously utilized, contributing to the model's overall efficiency.
Reduced Model Size and Parameters Compared to GPT-4
Mixtral 8x7B strategically differentiates itself from its larger counterparts, such as GPT-4, by adopting a scaled-down model size. While the nomenclature might imply a direct comparison in parameters with GPT-4, it is important to note that the name is slightly misleading.
The 8x7B model involves an eightfold increase only in the FeedForward blocks of the Transformer, and shares attention parameters, keeping the overall parameter count at 46.7 billion. This reduction in size does not compromise the model's performance but rather highlights Mistral AI's commitment to optimizing the model for practical applications.
32K Context Size for Robust Performance
To ensure robust performance across various tasks, Mixtral 8x7B maintains an impressive 32,000-token context window. This extensive context capacity allows the model to comprehend and analyze intricate patterns, making it suitable for a wide array of applications, from compositional tasks to data analysis and software troubleshooting.
Open Weights and Permissive Apache 2.0 License
A notable aspect contributing to Mixtral 8x7B's appeal is its commitment to openness. The model comes with open weights, enabling users to access and utilize the model with fewer restrictions compared to closed AI models from other entities. Furthermore, Mistral AI has adopted the permissive Apache 2.0 license for Mixtral 8x7B, underscoring its dedication to fostering a collaborative and accessible AI landscape.
Mixtral 8x7B's key features, including its innovative MoE architecture, efficient processing, optimized model size, extensive context capacity, and open-source approach, collectively position it as a trailblazer in the realm of large language models. These features not only contribute to its impressive performance but also align with Mistral AI's vision of democratizing advanced AI technologies for broader accessibility and application.
Development Journey
The journey of Mixtral 8x7B's development unfolds as a narrative of innovation, strategic decisions, and a commitment to accessibility. From an unconventional release strategy to fine-tuning efforts, the model's evolution reflects Mistral AI's dedication to pushing the boundaries of large language models.
Unconventional Release Strategy via Torrents
Mistral AI chose a distinctive path for the release of Mixtral 8x7B by opting for torrents instead of traditional launch methods. This unconventional strategy diverges from the orchestrated releases typical of major AI models, creating a stir within the AI community. The use of torrents for distribution not only reflects Mistral's unique approach but also serves as a statement about the model's capabilities, sparking conversations about the future of AI technology.
Reverse-Engineering Implementation within Hours of Initial Release
The agility and collaborative spirit of the AI community became evident as enthusiasts and developers swiftly reverse-engineered Mixtral 8x7B within hours of its initial release. This rapid turnaround showcases the responsiveness and engagement of the AI community, underlining the model's significance in stimulating quick and dynamic responses from developers.
Fine-Tuning for Instruction-Following Variant
As developers delved into Mixtral 8x7B's capabilities, a focus on fine-tuning emerged, particularly for an instruction-following variant. This nuanced approach highlights the adaptability of the model for specialized tasks, opening up possibilities for tailoring its performance to specific applications. The fine-tuning endeavors signify a stage of refinement and customization, catering to diverse user requirements.
Deployment on Fireworks.ai Platform
One of the notable milestones in Mixtral 8x7B's development journey is its deployment on the Fireworks.ai platform. This alternative platform offers a streamlined and user-friendly experience, providing quick access to the model shortly after the release of its weights. The collaboration with Fireworks.ai represents a strategic move to enhance accessibility, making the model available to a broader audience.
Ongoing Performance Optimization Efforts
The development journey of Mixtral 8x7B extends beyond its initial release, with Mistral AI actively engaged in ongoing performance optimization efforts. This commitment to refinement indicates a dedication to ensuring that the model not only meets but exceeds the expectations of users. The iterative optimization approach aligns with Mistral AI's pursuit of delivering a high-quality and evolving AI solution.
Mixtral 8x7B's development journey encapsulates a series of bold choices, collaborative engagement, and continuous refinement. From its unique release strategy to the deployment on user-friendly platforms, each step underscores Mistral AI's vision of making advanced AI models more accessible, engaging the community in the model's evolution, and maintaining a commitment to ongoing enhancement.
Comparative Analysis
In the landscape of large language models, Mixtral 8x7B emerges as a formidable contender, and its comparative analysis with other models sheds light on its unique strengths and performance metrics.
Benchmark Comparisons with Llama 2 70B and GPT-3.5
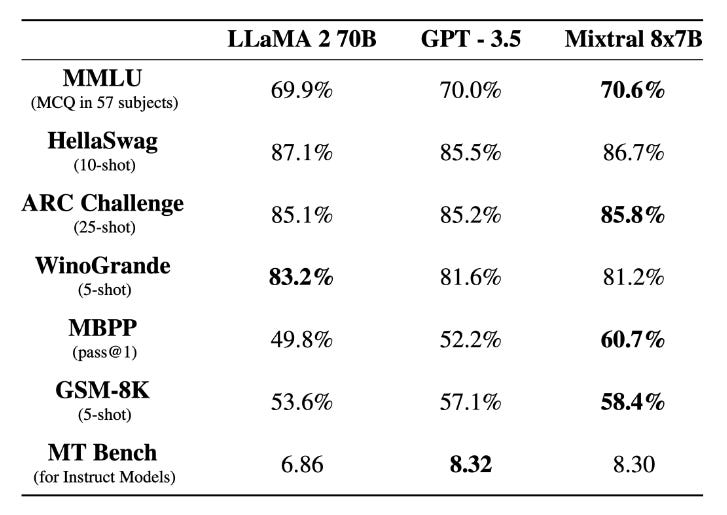
Mistral AI's Mixtral 8x7B has not only entered the arena but has positioned itself for direct comparison with established models. Benchmark comparisons reveal its competitive edge, showcasing performance metrics that challenge even larger counterparts like Llama 2 70B and GPT-3.5. The ability to match or exceed these models in specific benchmarks underlines Mixtral's prowess and efficiency. Mixtral matches or outperforms Llama 2 70B, as well as GPT3.5, on most benchmarks.


Compared to Llama 2, Mixtral presents less bias on the BBQ benchmark. Overall, Mixtral displays more positive sentiments than Llama 2 on BOLD, with similar variances within each dimension. - Mistral AI
Beyond raw benchmarks, an in-depth analysis of efficiency and performance metrics provides a comprehensive view of Mixtral 8x7B's capabilities. The model's ability to process a 32K token context window efficiently, coupled with its performance in various language tasks, contributes to its overall efficiency.
Benchmark Comparisons with Proprietary LLM
This benchmark highlights the outstanding relevance of an open-science model in the midst of consolidated names in the market. Mixtral instruction-tuned could reach a score of 8.30 on MT-Bench making it the best open-source model on the LMSys Leaderboard and generally a better option than great brands like Google (Gemini Pro).
MoE Architecture Compared to Traditional Models
The core of Mixtral 8x7B lies in its "Mixture of Experts" (MoE) architecture. A comparative analysis between MoE and traditional models reveals the advantages of this specialized approach.
The ability to route input data to different specialized neural network components, or "experts," allows for more efficient and scalable model training and inference. The efficiency gains become evident when comparing MoE to monolithic models with equivalent parameter counts.
Size Reduction Strategies and Parameter Sharing
Mixtral 8x7B employs size reduction strategies that contribute to its more manageable structure compared to its hypothetical larger counterparts like GPT-4. A comparative examination of size reduction strategies, particularly through parameter sharing among experts, highlights Mistral AI's thoughtful design choices. The model's reduced size, achieved without compromising performance, stands out as a key feature that distinguishes it in the realm of large language models.
Applications of Mixtral 8x7B
Mixtral 8x7B stands out for its remarkable versatility, making it a powerful tool across diverse domains and tasks. The model excels in:
Compositional Tasks
Mixtral model showcases a heightened ability to understand and generate content for compositional tasks. Its advanced language processing capabilities enable it to tackle complex instructions and provide coherent and contextually relevant responses.
Data Analysis
Leveraging its vast parameter count and Mixture of Experts model architecture, Mixtral 8x7B proves instrumental in data analysis tasks. The model can interpret intricate data patterns, generate insights, and contribute to decision-making processes.
Troubleshooting
The model's proficiency extends to troubleshooting scenarios. Whether it's diagnosing technical issues, providing solutions, or offering guidance, Mixtral 8x7B exhibits a problem-solving capacity across various contexts.
Programming Assistance
Developers and programmers benefit from Mixtral 8x7B's capabilities in understanding and generating code snippets. The model aids in coding tasks, offering suggestions, and enhancing the efficiency of the development process.
Multilingual Support
One of the standout features of Mixtral 8x7B is its robust multilingual support. The model is proficient in understanding and generating content in various languages like French, German, Spanish, Italian, and English.
This expansive language repertoire positions Mixtral 8x7B as a valuable resource for users across different linguistic backgrounds, fostering seamless communication and interaction in multiple languages.
Mixtral 8x7B's applications span a wide spectrum, emphasizing its adaptability and proficiency in addressing diverse user needs. Its multilingual capabilities and comparative advantages solidify its position as a leading language model in the AI landscape.
Technical Specifications of Mixtral 8x7B
Model Structure Details
Mixtral 8x7B boasts a sophisticated architecture designed to optimize performance and efficiency. The key model structure details include:
Dimensions (dim): The embedding space dimension is set at 4096, allowing for a high-dimensional representation of language and context.
Layers (n_layers): Mixtral 8x7B comprises 32 layers, contributing to its depth and capacity for hierarchical learning.
Heads (n_heads): The model incorporates multi-head attention with 32 attention heads, facilitating parallelized processing and capturing diverse aspects of input information.
Head Dimension (head_dim): Each attention head has a dimension of 128, enabling the model to focus on specific patterns and relationships within the input data.
Hidden Dimension (hidden_dim): With a hidden dimension of 14336, Mixtral 8x7B accommodates intricate feature representations, enhancing its overall expressive power.
Number of Key-Value Heads (n_kv_heads): The model employs 8 key-value heads, contributing to the Mixture of Experts (MoE) architecture's efficiency.
Normalization Epsilon (norm_eps): Set at 1e-05, the normalization epsilon ensures stable training and consistent performance.
Vocabulary Size (vocab_size): Mixtral 8x7B operates with a vocabulary size of 32000, encompassing a diverse range of linguistic elements.
Mixture of Experts (MoE) Configuration: Mixtral 8x7B implements an MoE architecture with 8 experts, each handling 7 billion parameters. Notably, token inference involves only 2 experts, contributing to processing efficiency.
Efficient GPU Utilization
Mixtral 8x7B is designed with efficiency in mind, optimizing GPU utilization for enhanced performance. Key aspects include:
8-Bit Floating Point Regime (fp8): The model supports the 8-bit floating-point regime (fp8), contributing to reduced memory requirements and faster computation without compromising accuracy.
GPU Compatibility: Mixtral 8x7B demonstrates efficient GPU utilization, making it compatible with various GPU configurations. The model's design allows for effective scaling on GPUs with a minimum of 86GB VRAM.
Adaptability to Different Deployment Configurations on Fireworks.ai
Mixtral 8x7B's versatility extends to its adaptability to different deployment configurations on the Fireworks.ai platform. The model seamlessly integrates into the Fireworks.ai environment, allowing users to leverage its capabilities for various applications.
The technical specifications of Mixtral 8x7B highlight a well-crafted model structure, efficient GPU utilization strategies, and adaptability to different deployment scenarios. These technical nuances contribute to the model's overall performance, making it a standout player in the landscape of the latest models of similar capabilities.
Adaptability to Consolidated Datasets
Taking advantage of these advances on Mixtral, a quick adaptation and versatility in training frameworks emerged, generating high-performance models like Dolphin 2.6 Mixtral-8x7B and OpenHermers Mixtral-8x7B. Both models are based mainly on the OpenHermes dataset, for a variety of tasks. These new fine-tuned models have been making noise in the tech world for good in terms of advancing capabilities, and for bad due to their “uncensored” nature with unfiltered responses generating ethical concerns.
Future Prospects
Mistral AI's dedication to continuous performance optimization positions Mixtral 8x7B at the forefront of evolving language models. The commitment to refining and enhancing the model's capabilities signifies a proactive approach to addressing emerging challenges and user needs. Mistral AI recognizes the dynamic nature of the AI landscape and actively engages in ongoing efforts to optimize Mixtral 8x7B.
The prospects for Mixtral 8x7B encompass several key aspects:
1. Performance Refinement: Mistral AI aims to further refine the model's performance, focusing on supervised fine-tuning and addressing potential areas for optimization. This commitment ensures that Mixtral 8x7B continues to deliver cutting-edge results across various applications.
2. Feature Expansions: Anticipate potential developments and feature expansions that may broaden Mixtral 8x7B's applicability. Mistral AI's forward-looking approach includes exploring new functionalities to meet the evolving demands of users and industries.
3. Adaptive Capabilities: As AI applications evolve, Mistral AI remains dedicated to ensuring Mixtral 8x7B's adaptive capabilities. This involves staying abreast of technological advancements and user feedback to implement updates that enhance the model's adaptability to diverse scenarios.

I also host an AI podcast and content series called “Pioneers.” This series takes you on an enthralling journey into the minds of AI visionaries, founders, and CEOs who are at the forefront of innovation through AI in their organizations.
To learn more, please visit Pioneers on Beehiiv.
Conclusion
Mixtral 8x7B stands as a testament to Mistral AI's commitment to pushing the boundaries of large language models. Its unique features, such as the Mixture of Experts (MoE) architecture, 8 experts with 7 billion parameters, and efficient processing, contribute to its exceptional performance across various domains.
Looking to the future, Mistral AI's commitment to ongoing optimization ensures that Mixtral 8x7B remains a frontrunner in the AI landscape. As Mistral AI continues to evolve and adapt Mixtral 8x7B, we can expect further advancements, solidifying its impact on the AI community and industry at large. Mixtral 8x7B not only represents a remarkable achievement in AI technology but also sets the stage for continued innovation and progress in natural language processing.
Mixtral 8x7B by Mistral AI is truly impressive! With its innovative MoE architecture, it's super efficient and versatile. Multilingual support is a big plus. And the unique release strategy was really cool.