
Making unstructured data AI ready: A guide for enterprises
Unstructured data poses challenges for AI. Learn how to clean and preprocess unstructured data to make it AI-ready


Key Takeaways
Unstructured data is a challenge. Most enterprise data is unstructured, making it difficult to analyze and leverage for AI.
AI depends on clean data. AI models need clean, high-quality data to perform effectively. Messy data can lead to subpar results.
Data silos and redundancies. These issues hinder AI development and operational efficiency.
RAG requires clean data. Retrieval-augmented generation (RAG) benefits from well-organized data to produce accurate results.
AI agents for data preparation. AI agents can automate data cleaning and preparation, making unstructured data AI-ready.

Last year, I started Multimodal, a Generative AI company that helps organizations automate complex, knowledge-based workflows using AI Agents. Check it out here.
90%. That’s the amount of enterprise data that is unstructured, messy, and siloed. Over the years, I've witnessed firsthand how organizations grapple with voluminous and disparate data. Now that all of them are moving to adopt AI solutions in multiple areas, this scattered unstructured data poses an even greater challenge.
AI models thrive on good, clean data. But cleaning massive volumes of complex enterprise data is incredibly difficult, which is why most AI deployments in the enterprise either fail or deliver subpar performance. But AI can actually help with data cleanup too.
At Multimodal, one of the key things I’ve been developing is an unstructured data AI Agent that can clean and preprocess data for downstream processing by sophisticated AI models. Let’s talk a bit more about cleaning, preprocessing, and storing unstructured data to make it ready for AI.
The real challenge of enterprise data

Unlike structured data, which fits neatly into databases, unstructured data includes a wide range of formats such as emails, social media posts, analyst reports, graphs, charts, financial statements, and more. This diversity makes it difficult to organize and analyze, yet it holds immense potential for insights.
Extracting relevant information from unstructured sources is crucial for decision-making, risk assessment, and compliance. Traditional methods struggle to handle the volume and complexity of this data effectively.
AI can help generate excellent insights from these sources and automate complex workflows. But downstream Gen AI work to do all this requires very high-quality data upfront. Bad data leads to bad outcomes. Great data improves the odds of better outcomes downstream. Unfortunately, enterprises are full of bad data.
Take, for example, the financial services sector, where data silos are a notorious hurdle. Banks and financial institutions often store analyst reports, customer information, transaction records, and compliance documents in isolated systems, making it difficult to gain a holistic view of the customer journey or streamline operations. This fragmentation not only hampers operational efficiency but also limits the ability to leverage AI for predictive analytics and personalized services.
Similarly, within insurance, the challenge is compounded by how companies have and store unstructured data. Claims, policy documents, and customer interactions often exist in formats that are not readily compatible with traditional data processing tools. This lack of structure poses a significant challenge for AI systems.
Addressing these challenges requires a strategic approach to data integration and management, ensuring that enterprises can fully harness the power of AI. By transforming messy data into an AI-ready asset, organizations can unlock new levels of efficiency and innovation, paving the way for scalable and impactful AI solutions.
Messy data = Bad enterprise AI

Data Silos
Data silos are a pervasive issue in many organizations, where information is isolated across different departments or systems. This separation can significantly hinder AI development and operational efficiency.
For example, in financial services, unstructured data fragmentation prevents the creation of a comprehensive customer profile, which is essential for delivering personalized services and conducting accurate risk assessments.
Redundancies
Redundancies in data storage and management can further exacerbate inefficiencies. When multiple copies of the same data exist in different systems, it not only wastes storage resources but also complicates data management processes.
This is particularly problematic in sectors like insurance, where claims processing and policy management rely on accurate and up-to-date information. If data is duplicated or outdated, it can slow down AI models made for claims processing and lead to errors in risk assessment models.
RAG and enterprise AI
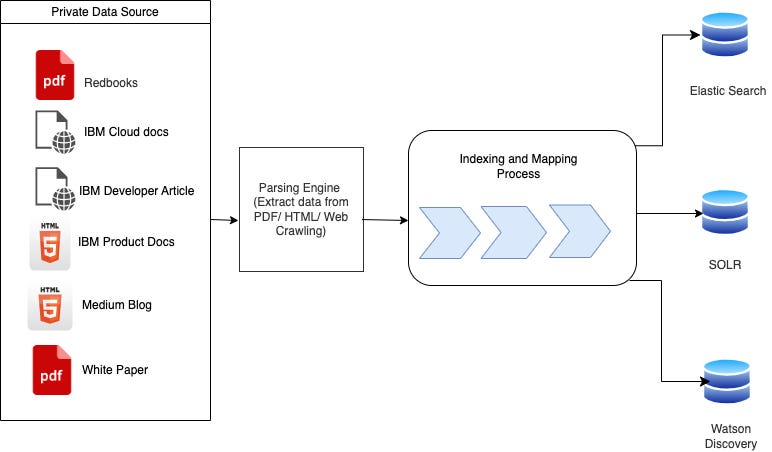
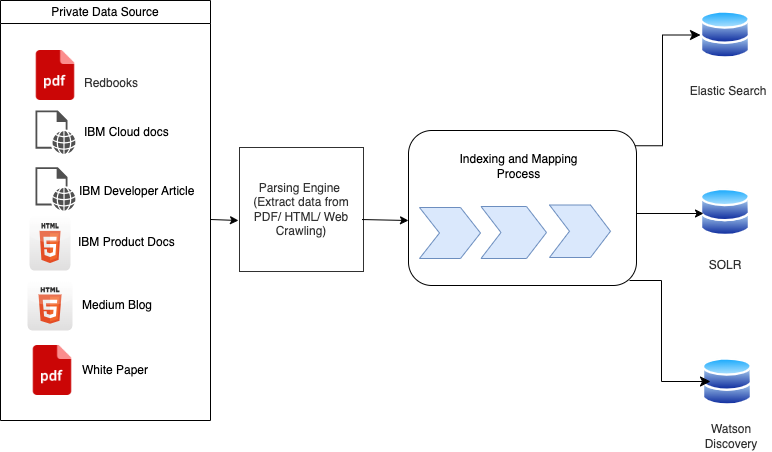{kind=link}
Retrieval augmented generation (RAG) is a crucial technology being used to analyze unstructured data by enhancing AI models with real-time data retrieval capabilities. It’s also essential for building more sophisticated AI models that automate tasks like loan underwriting, claims, and more. However, implementing RAG effectively requires clean and well-organized data. Messy data can lead to inaccuracies in the retrieval process, resulting in less relevant and reliable AI-generated responses.
A lot of financial institutions I work with want to build or use RAG systems to help with unstructured data analysis. However, handling vast amounts of unstructured data demands significant computational resources and sophisticated scaling strategies. Additionally, maintaining data relevance and accuracy is an ongoing challenge, especially as data sets continue to evolve.
Clean data is essential for RAG
For RAG systems to perform optimally, it is crucial to preprocess unstructured data to ensure it is clean and high-quality. This involves techniques such as noise detection and duplicate identification, which help filter out irrelevant or erroneous information that could compromise the accuracy of AI outputs.
By prioritizing data quality and organization, enterprises can maximize the effectiveness of RAG systems, enabling them to generate contextually relevant and accurate responses.
A client I was working with at Multimodal was interested in using unstructured data like news, analyst reports, social media sentiment, and more to generate alpha. However, just feeding all of this data into a Gen AI model with RAG would never work just because of how scattered and varied these formats are. With our AI agent specializing in data cleaning and preprocessing for RAG, they were able to achieve excellent results.
AI Agents for unstructured data processing
You do need clean data to power AI applications. But the good news is that you don’t have to clean unstructured data manually. AI Agents specializing in preparing data for downstream LLM processing work better and faster than manual methods for doing this. This in turn makes analyzing unstructured data easier for advanced Gen AI models.
Role of AI in data cleaning and preparation
AI agents are pivotal in transforming unstructured data into a format that is ready for advanced unstructured data analytics tools and integration into enterprise systems. Techniques such as Natural Language Processing (NLP) and machine learning automate the cleaning and preparation of data, ensuring it is accurate and accessible downstream.
NLP is particularly useful in processing text-heavy unstructured data, such as emails and reports. By parsing and understanding human language, NLP can extract relevant information and convert it into structured data that can be easily analyzed.
Machine learning models further enhance this process by identifying patterns and anomalies within the data. These models can automatically detect and correct errors, fill in missing values, and remove duplicates, significantly reducing the time and effort required for data preparation.
Making data ready for LLMs and RAG
To leverage Large Language Models (LLMs) and Retrieval-Augmented Generation (RAG) applications effectively, data must be meticulously prepared. AI agents play a crucial role in this transformation by executing several key steps:
1. Data normalization: AI agents standardize data formats, ensuring consistency across various data sources. This is essential for LLMs, which require uniform data to generate accurate insights.
2. Integration and validation: AI systems integrate data from multiple sources, validating its accuracy and relevance. This step is critical for RAG.
3. Noise detection and filtering: AI agents identify and filter out irrelevant or erroneous data, maintaining the quality and integrity of the dataset. This ensures that LLMs and RAG systems operate on high-quality data, producing reliable outputs.
Benefits of AI-ready data for enterprises
The number one benefit of clean, AI-ready data is that it opens up the possibility to develop a super-efficient AI application downstream. For example, if a financial institution is looking to automate complex workflows with Gen AI, it first needs clean data to train the model. AI-ready data would make the training process faster and cheaper.
Better predictive models: When data is clean, well-structured, and accessible, AI systems can generate more accurate insights and predictions. Financial institutions can leverage AI to analyze market trends and customer behavior, insurance companies can automate underwriting, etc.
Easily building efficient chatbots: AI-ready data also allows enterprises to deploy AI-powered chatbots that engage in natural, human-like conversations with customers and employees. Think ChatGPT or Perplexity, but with context on company data. These chatbots provide instant responses to queries, troubleshoot issues, and offer personalized product recommendations.

I also host an AI podcast and content series called “Pioneers.” This series takes you on an enthralling journey into the minds of AI visionaries, founders, and CEOs who are at the forefront of innovation through AI in their organizations.
To learn more, please visit Pioneers on Beehiiv.
What the future of processing unstructured data looks like
I have observed several key trends shaping the landscape of AI data processing and integration. First, the adoption of API-first architectures is gaining momentum. That’s something we’re building at Multimodal too.
The rise of RAG is transforming how enterprises leverage AI. Even enterprises that choose to build their own AI models need clean data. Spending time and money on first cleaning the data and then building the model can be super inefficient. In those cases, I usually recommend people use a data processing partner with a sophisticated AI model to just prepare it for RAG or AI.
Next week, I’ll dive deeper into the capabilities of an unstructured data AI model, what it should ideally do to process unstructured data, and how it enhances enterprise AI systems.
Until then,
Ankur.