
LLaMA 1 vs LLaMA 2: A Deep Dive into Meta’s LLMs
Discover Meta’s journey into the world of LLMs and how LLaMA 2 compares to its successor, LLaMA 1.


Key Takeaways
Meta announced LLaMA 1 in February 2023 as a response to OpenAI's and Google's language models.
LLaMA 1 focused on efficiency by using fewer computing resources while still maintaining high performance, comparable to GPT-3 despite being a smaller model. This model was only available through a non-commercial license for research purposes, primarily.
Meta received over 100,000 requests to provide access to LLaMA 1, so they developed its successor: LLaMA 2. LLaMA 2 was released in July 2023 and is available with a commercial license.
LLaMA 2 was able to achieve similar performance to GPT-3.5 on various academic benchmarks, but performed much worse than GPT-4, particularly in coding tasks.
LLaMA 2 achieved much lower safety violation scores than its competitors, making it a big step forward in adhering to the ethical guidelines of LLMs.
LLaMA 2 is an improvement from LLaMA 1 in almost every aspect, and Meta will likely release a newer LLaMA model down the line.

This post is sponsored by Multimodal, an NYC-based startup setting out to make organizations more productive, effective, and competitive using generative AI.
Multimodal builds custom large language models for enterprises, enabling them to process documents instantly, automate manual workflows, and develop breakthrough products and services.
Visit their website for more information about transformative business AI.
In July 2023, Meta announced LLaMA 2, an updated version of its predecessor, LLaMA 1. These large language models (LLMs) are Meta’s response to popular LLMs like GPT-4. LLaMA 2 is an open-source model available for commercial and research use.
LLaMA 2 brings up the question of how it stacks up to LLaMA 1 and if it’s a significant improvement over the original model.
Is it a massive leap forward from the original model, or just a small step in the ongoing evolution of LLMs?
Let’s take a look at both of the LLaMA models to see if Meta’s latest LLM lives up to the hype.
LLaMA 1
Before we take a look at LLaMA 2, we’ll need to have a look at its predecessor, LLaMA 1, to make better comparisons.
Meta first announced the release of LLaMA 1 in February 2023 in a blog post and a research paper. It uses the transformer architecture and consists of four LLMs that have varying model sizes from 7B to 65B.
It was trained on 1.4 trillion tokens from various publicly available online data sources, such as Common Crawl and Github. It also used Wikipedia in 20 different languages as a data source for training. One key advantage that LLaMA 1 has over its competitors is that it uses fewer computing resources.
Notably, LLaMA 1 had high performance on various benchmarks in comparison to other LLMs like PaLM, Chinchilla, and GPT-3.
This can be seen in the table below, which shows the performance of LLaMA 1 on common sense reasoning tasks compared to other LLMs.

Additionally, LLaMA 1 has been fine-tuned to carry out various tasks. It also performed well on other benchmark tasks such as reading comprehension, mathematical reasoning, and code generation. Even though LLaMA 1 was a smaller model than GPT-3, it still achieved similar performance.
Although it’s able to keep up with its LLM competitors when it comes to these benchmarks, it has the same issue of generating incorrect information.
Specifically, LLaMA 1 was designed for research purposes, so it is only available through a non-commercial license, with researchers and developers having to apply for access.
Now that we’ve explored the first version of LLaMA, let’s see how the second version builds upon this foundation.
LLaMA 2

With over 100,000 requests to access LLaMA 1, Meta decided to develop the open-source language model LLaMA 2 and release it in July 2023. Contrary to LLaMA 1, LLaMA 2 is available via a commercial license and through providers such as Hugging Face.
As a result, researchers and developers are encouraged to collaborate to find new applications with LLaMA 2. Not only are the LLaMA 2 models open-source, but Meta also provides model weights and starting code for pre-trained LLaMA models. This lets developers and researchers build upon AI models more easily.
Meta also developed a fine-tuned LLaMA 2 model called LLaMA-2-chat, which was trained on over 1 million human annotations. The primary use for this fine-tuned variant is in chatbot applications.
LLaMA 2 Training Process
LLaMA 2 uses most of the same model architecture and presetting training as LLaMA 1.
However, one major difference from LLaMA 1 is that LLaMA 2 used reinforcement learning from human feedback (RLHF) during its training process. As a result of learning through interactions with humans, the model is more helpful in conversations than LLaMA 1.
LLaMA 2 was fine-tuned with 40% more data than LLaMA 1, where the data consisted of 1.4 million tokens. Moreover, the LLaMA 2 fine-tuned models are trained on 2 trillion tokens and have double the context length of LLaMA 1. These newer models have parameters ranging from 7B to 70B, while GPT-3 has 175B parameters.
Similar to LLaMA 1, LLaMA 2 is efficient by providing high performance despite being a smaller model compared to its competitors.
Additionally, Meta was cautious about using sensitive data during the training of LLaMA 2, so they removed data from sites that have a lot of personal information. This helps ensure LLaMA 2 follows ethical guidelines by avoiding the use of personal data.
Safety was a huge priority for Meta during development, with LLaMA 2 achieving a much lower violation percentage when compared to other LLMs, with all the LLaMA 2 models staying below the 10% threshold.

This is a huge step forward in LLM development, as the LLaMA 2-chat models drastically improve safety even when compared to closed-source models.
LLaMA 2 Performance
When we take a closer look at LLaMA 2’s performance against GPT-4 in various academic benchmarks, LLaMA currently falls short.
In particular, LLaMA 2’s performance on coding is lacking in comparison to other LLMs. LLaMA 2 can keep up with GPT-3 in almost every benchmark aside from coding, but has much lower performance than GPT-4 across the board.

When it comes to comparing LLaMA 2 with closed-source powerhouse LLMs like GPT-4, it doesn’t perform as well yet. However, when compared to other open-source language models like Falcon, LLaMA 2 shows significantly better performance, making it a contender for some of the most powerful open-source models currently available.
Which one has the upper hand?
Some of the major advantages of LLaMA 2 over its successor include:
Improved training and performance: LLaMA 2 was trained on 40% more data and has twice the context length, so it can better understand complex language structures. It also performs better at tasks like reasoning, coding, and proficiency.
Open-source: With LLaMA 2 being open-source and available for both commercial and non-commercial use, developers and researchers can find further innovative uses for the model.
Accessibility: Meta partnered with various providers, such as Microsoft, to improve the accessibility of LLaMA 2. It’s available in the Azure AI model catalog and is optimized to run locally on Windows to provide a better experience for users.
Resources for responsible use: With ethical concerns rising with recent AI usage, Meta provides various resources to ensure responsible use of their language model, including red-teaming exercises (testing the safety of the models by finding any weaknesses or vulnerabilities) and a transparency schematic.
Increased learning from human interactions: The introduction of RLHF into the training process of LLaMA 2 makes it more proficient at learning from human interactions.
Although LLaMA 2 has several advantages over LLaMA 1, the pretraining setting and model architecture are mostly the same as in LLaMA 1, with the main difference being the doubled context length.
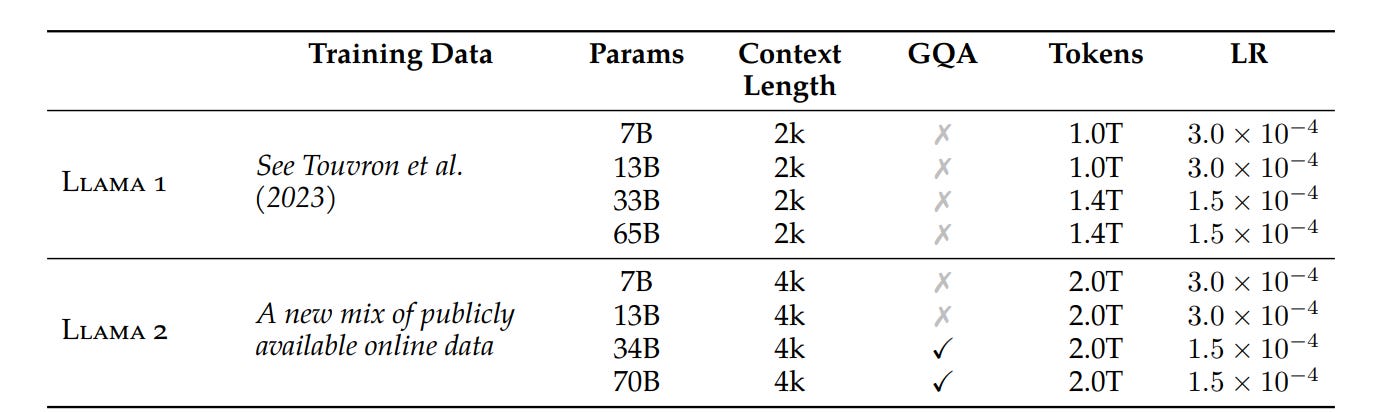
The different parameters, context lengths, and tokens of the LLaMA 1 and LLaMA 2 models. (Source)
Additionally, the bigger LLaMA 2 models (34B and 70B) use grouped-query attention (GQA). This allows for improved inference scalability, which is the model's ability to quickly process several prediction requests.
While LLaMA 1 was mostly focused on academic purposes by being issued to research organizations upon request, LLaMA 2 takes the opposite approach by being available for research and commercial use.
As a result, LLaMA 2 is a more versatile language model than LLaMA 1, due to its wider range of applications and use-cases. Some applications include content generation, personalized recommendations, and customer service automation.
Looking Ahead
Meta’s answer to Google’s BARD and OpenAI’s ChatGPT has proved to be an interesting piece of the LLM puzzle. LLaMA 1 was already able to outperform GPT-3 with fewer computing resources.
Although LLaMA 2 doesn’t outperform GPT-4, it still blows its open-source LLM competitors out of the water, especially when considering safety aspects. This makes LLaMA 2 a huge step forward in LLM development, as organizations now have the option to use a powerful open-source LLM that offers more customizability than popular closed-source models.
With LLaMA 2’s increased training data, it’s able to perform significantly better than its predecessor in several benchmarks. Overall, LLaMA 2 is a more flexible and practical tool than LLaMA 1, with increased performance and accessibility through a commercial license.
That raises the question: if Meta was willing to develop LLaMA 2 as a response to the 100,000 requests put in for access to LLaMA 1, does that mean we will see a LLaMA 3 at some point in the near future?
It’s reasonable to assume Meta will continue its venture into the world of LLMs and eventually release a more refined LLaMA model.
With LLaMA 2 currently unable to outperform its biggest competitor, GPT-4, there are high chances of Meta creating a new LLaMA model that can keep up with state-of-the-art closed-source LLMs.