
Google TPUs vs. AWS Trainium & Inferentia vs. NVIDIA GPUs
Check out this detailed comparison of hyperscaler AI training hardware by Google, Azure, and NVIDIA, learning which use cases they work best for.


Key Takeaways
1. Specialized AI hardware, such as AWS Trainium, Google TPUs, and NVIDIA GPUs, is essential for efficiently handling complex AI workloads and delivering high performance at scale.
2. Each platform—AWS, Google Cloud, Azure, and NVIDIA—offers unique strengths, making it crucial for enterprises to choose based on specific use cases and existing infrastructure.
3. Cost efficiency is a significant differentiator among platforms, with Google TPU v5e and AWS Inferentia2 providing compelling options for budget-conscious organizations.
4. The integration capabilities of Azure's NVIDIA GPU offerings streamline deployment for enterprises already embedded in the Microsoft ecosystem.
5. As AI applications evolve, the demand for custom AI chips and hybrid solutions will grow, particularly in sectors like finance and insurance where performance and regulatory compliance are critical.

Last year, I started Multimodal, a Generative AI company that helps organizations automate complex, knowledge-based workflows using AI Agents. Check it out here.
In recent years, we've witnessed an unprecedented surge in generative AI technologies. But here's the thing: as AI models grow more sophisticated, the demand for specialized hardware to train and run these models efficiently has skyrocketed. We're talking about purpose-built chips designed to handle the unique computational needs of AI workloads.
On one side, we have the hyperscalers – AWS, Google Cloud, and Microsoft Azure – each developing their AI-optimized hardware. On the other, we have NVIDIA, the long-standing champion of GPU acceleration.
Why hardware matters for enterprise applications

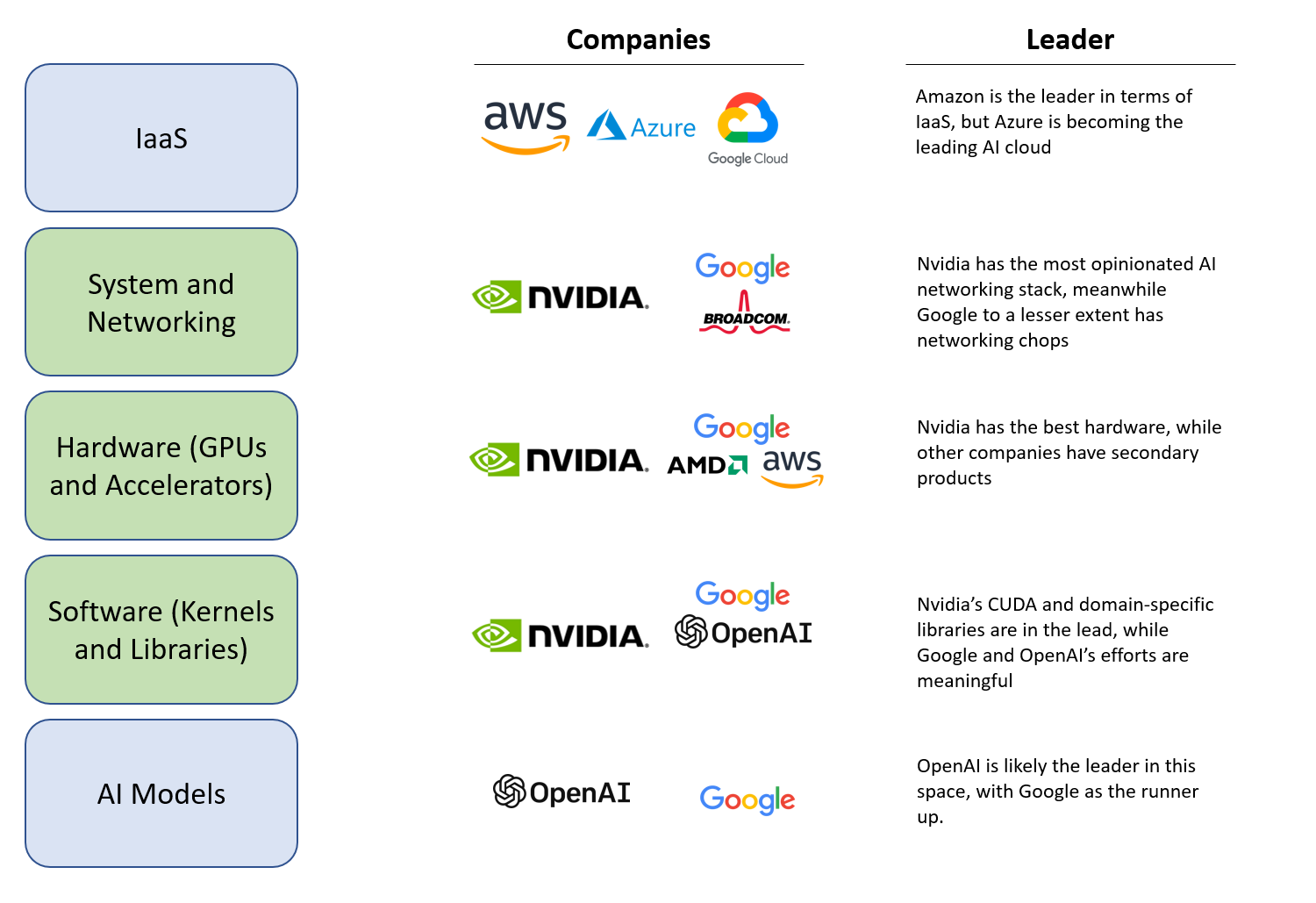{kind=link}
Let's break down why this matters for enterprises, especially in data-intensive sectors like finance and insurance:
1. Performance at scale
When you're dealing with large language models or complex neural networks for risk assessment, you need hardware that can deliver high performance at scale. The difference between running a model in hours versus days can have significant business implications.
2. Cost efficiency
AI training and inference can be expensive. Purpose-built hardware like AWS Trainium or Google's Cloud TPUs can offer substantial cost savings compared to general-purpose computing resources.
3. Energy efficiency
As AI workloads grow, so does their energy consumption. More efficient hardware not only reduces costs but also aligns with corporate sustainability goals – a growing concern in the financial sector.
4. Specialized capabilities
Different AI tasks require different optimizations. For instance, the hardware best suited for training a fraud detection model might not be ideal for running real-time inference on customer transactions.
AWS hardware: powering the next generation of AI
AWS has been making waves with its purpose-built chips for AI workloads. Let's dive into AWS Trainium and AWS Inferentia:
AWS Trainium2: the AI training powerhouse
Here's why AWS Trainium2 is turning heads in the industry:
Specifications and performance
Estimated 650 TFLOPS per chip
96 GB of high bandwidth memory (HBM)
4x higher training performance than its predecessor
2x better performance per watt
3x more memory capacity
These specs translate to some serious muscle for handling complex AI models. But what does this mean for your business?
Best applications
1. Natural Language Processing (NLP):
Trainium2 excels at training large language models. If you're in finance or insurance, think about the potential for processing complex legal documents or analyzing customer feedback at scale.
2. Computer vision
From analyzing medical images to processing satellite data for insurance claims, Trainium2's performance boost can significantly speed up your computer vision workflows.
3. Generative AI
With its increased memory and processing power, Trainium2 is well-suited for training generative models that can create content or assist in product design.
Integration and ecosystem
What really sets Trainium2 apart is its seamless integration with the AWS ecosystem. It works hand-in-hand with AWS Inferentia2 for inference workloads, creating an end-to-end solution for AI model development and deployment.
The AWS Neuron SDK makes it easy for developers to optimize their machine-learning models for Trainium2, reducing the learning curve and accelerating time-to-value.
We're seeing a shift from general-purpose GPUs to application-specific integrated circuits (ASICs).
For enterprises, especially in data-intensive sectors like finance and insurance, this means:
1. More cost-effective AI training at scale
2. Ability to tackle more complex AI problems
3. Faster iteration on AI models, leading to quicker innovation
AWS Inferentia2: specialized AI inference
When it comes to AI inference workloads, AWS Inferentia2 is making waves in the cloud computing space. Efficient inference is often the key to unlocking real-world value from your AI models.
Specifications and performance
Up to 2.3 petaFLOPS at BF16 or FP16 data types (for the largest inf2.48xlarge instance)
Up to 384 GB of shared accelerator memory
A high-bandwidth, chip-to-chip interconnect for scaling large models across multiple chips
What sets Inferentia2 apart is its ability to handle complex AI models with impressive efficiency. Compared to GPU-based instances, Inferentia2 can offer significant cost savings while maintaining high performance.
Best applications
Inferentia2 shines in a variety of inference workloads, particularly:
1. Natural Language Processing (NLP)
Large language model inference
Real-time text generation and summarization
Sentiment analysis at scale
2. Computer vision
Image classification and object detection
Video analysis for security applications
Medical image processing
3. Recommendation systems
Real-time product recommendations in e-commerce
Personalized content delivery for streaming services
4. Time series analysis
Financial forecasting
Anomaly detection in IoT sensor data
The chip's architecture is optimized for these types of workloads, allowing for faster and more cost-effective inference compared to general-purpose GPUs.
Here are some real-world examples of how companies are leveraging Inferentia2:
This Japanese financial technology company reported impressive results using Amazon EC2 Inf1 instances (powered by the first-generation Inferentia):
- 97% reduction in inference latency
- Significant cost savings compared to GPU-based instances
While this example is for Inferentia1, it showcases the potential of AWS's custom AI chips for inference workloads.
The introduction of Inferentia2 represents a significant step forward in AWS's AI hardware strategy. As AI models continue to grow in size and complexity, purpose-built chips like Inferentia2 will play an increasingly crucial role in making AI applications faster, more efficient, and more cost-effective.
For enterprises looking to scale their AI inference workloads, Inferentia2 offers a compelling alternative to traditional GPU-based solutions. Its ability to handle large language models and complex neural networks with high efficiency makes it particularly attractive for companies dealing with NLP, computer vision, and other data-intensive AI applications.
Google Cloud TPUs: powering next-gen AI
Google's Tensor Processing Units (TPUs) have been game-changers in the world of machine learning and artificial intelligence.
TPU v4: the powerhouse for large-scale AI
Specifications and performance
Google's TPU v4 is a purpose-built chip designed to deliver high performance for AI training and inference workloads. Here are the key specs:
Performance: 275 teraFLOPS (BF16 or INT8) per chip
Memory: 32 GB of high bandwidth memory (HBM) per chip
Memory bandwidth: 1200 GB/s
Interconnect: 3D torus network for efficient scaling
What sets TPU v4 apart is its ability to scale seamlessly. A single TPU v4 pod can contain up to 4096 chips, delivering a staggering 1.1 exaFLOPS of compute power. This level of performance is crucial for training large language models and other compute-intensive AI applications.
Best applications
TPU v4 excels in large-scale training scenarios, particularly:
1. Large Language Models
Training massive models like BERT, T5, and GPT-style architectures.
2. Computer vision
Processing and analyzing vast datasets of images and videos.
3. Scientific simulations
Running complex simulations for fields like climate modeling or drug discovery.
4. Recommendation systems
Training sophisticated recommendation models on massive user datasets.
Benchmarks and comparisons
Google has published several benchmarks showcasing TPU v4's performance. In one notable example, they trained a 1.6 trillion parameter language model using TPU v4 pods, demonstrating the system's ability to handle extreme-scale AI workloads.
Compared to its predecessor, TPU v3, the v4 offers:
- 2.7x more performance per chip
- 3x higher memory bandwidth
While direct comparisons with other AI accelerators like NVIDIA GPUs or AWS Trainium are complex due to different architectures and use cases, TPU v4 has shown competitive performance in large-scale training scenarios.
TPU v5e: balancing performance and cost-efficiency
Specifications and cost-efficiency
The TPU v5e is Google's latest offering, designed to provide a more cost-effective solution.
Performance: Specific FLOPS not disclosed, but Google claims up to 2x higher training performance per dollar compared to TPU v4
Memory: Not specified, but likely similar or improved from v4
Cost-efficiency: Up to 2.5x better inference performance per dollar for LLMs and generative AI models
Best applications
TPU v5e is well-suited for:
1. Medium to large-scale training
Ideal for organizations that need significant compute power but may not require the extreme scale of TPU v4.
2. Inference workloads
Particularly efficient for running inference on large language models and generative AI applications.
3. Mixed workloads
Versatile enough to handle both training and inference tasks cost-effectively.
Performance improvements
While Google hasn't released detailed performance comparisons, they've highlighted several improvements in the TPU v5e:
- Better performance per dollar for both training and inference compared to TPU v4
- Enhanced support for sparsity and quantization, improving efficiency for certain workloads
- Improved integration with Google Kubernetes Engine (GKE) for easier deployment and management
Real-world impact
Cohere: This AI company used Cloud TPU v4 to train their large language models, reporting significant improvements in training speed and cost-efficiency compared to their previous GPU-based infrastructure.
For enterprises considering their AI infrastructure options, Google's TPUs offer a compelling mix of raw performance and cost-efficiency. Whether you're training massive language models or deploying inference at scale, the combination of TPU v4 and v5e provides flexible options to meet diverse AI workloads.
Azure AI infrastructure: powering enterprise AI at scale
Let's dive into what makes Azure's offerings stand out, especially when it comes to NVIDIA GPU integration and their AI-optimized infrastructure.
NVIDIA GPU offerings on Azure
Azure's partnership with NVIDIA has resulted in a powerful lineup of GPU-accelerated instances, perfect for tackling diverse AI workloads.
Specifications and performance
Azure offers a range of NVIDIA GPUs, but let's focus on two powerhouses:
1. NVIDIA A100
- 80GB of high bandwidth memory (HBM2e)
- Up to 312 TFLOPS for AI inference
- 1.6 TB/s memory bandwidth
2. NVIDIA H100
- 80GB of HBM3 memory
- Up to 1000 TFLOPS for AI training and inference
- 3.35 TB/s memory bandwidth
These specs translate to some serious muscle for handling complex AI models and large-scale machine learning workloads.
Best applications
The A100 and H100 GPUs on Azure excel in a variety of AI applications:
1. Large Language Models
Training and fine-tuning massive models like GPT-3 and BERT.
2. Computer vision
Processing and analyzing vast datasets of images and videos.
3. Deep learning
Training complex neural networks for various applications.
4. High-Performance Computing
Running scientific simulations and data-intensive computations.
Integration with Azure services
What sets Azure's GPU offerings apart is their seamless integration with other Azure services:
- Azure Machine Learning: Simplifies the process of building, training, and deploying models.
- Azure Kubernetes Service (AKS): Enables easy scaling of GPU-accelerated containers.
- Azure Cognitive Services: Pre-built AI models that can be enhanced with custom GPU-accelerated solutions.
Azure's AI-optimized infrastructure
Beyond GPU offerings, Azure has developed a comprehensive AI-optimized infrastructure designed for enterprise-scale AI solutions.
Scalability and flexibility
Azure's AI infrastructure is built to scale:
Distributed training: Support for model parallelism and data parallelism across multiple GPUs and nodes.
Flexible deployment: Options for on-premises, cloud, and edge deployments.
Auto-scaling: Dynamically adjust resources based on workload demands.
Best applications
1. MLOps
Streamlining the machine learning lifecycle from development to production.
2. AI-powered analytics
Integrating AI models with big data processing for real-time insights.
3. IoT and Edge AI
Deploying models to edge devices for real-time processing.
Here’s a real-world example of Azure's AI infrastructure in action:
Novartis: The pharmaceutical giant leveraged Azure's AI infrastructure to accelerate drug discovery. They reported a 50% reduction in time required to analyze and prepare data for machine learning models.
For enterprises considering their AI infrastructure options, Azure offers a compelling mix of raw performance, scalability, and integration with existing Microsoft technologies.
NVIDIA Hardware: pushing the boundaries of AI compute
NVIDIA's hardware has consistently been at the forefront of AI acceleration. Let's dive into their latest offerings:
NVIDIA H200: the next-gen AI powerhouse
NVIDIA's H200 is the latest addition to their lineup of high-performance GPUs.
Specifications and performance improvements over H100
The H200 builds on the success of its predecessor, the H100, with some impressive upgrades:
Memory: 141 GB of HBM3e (High Bandwidth Memory)
Memory bandwidth: 4.8 TB/s (1.4x more than H100)
AI performance: Up to 2.5x faster than H100 for some LLM workloads
What sets the H200 apart is its massive memory capacity and bandwidth, which are crucial for handling the increasingly large AI models we're seeing in the field.
Best applications
The H200 excels in compute-intensive AI workloads, particularly:
1. LLMs
Training and inference for massive models like GPT-4 and beyond.
2. High-Performance Computing (HPC)
Scientific simulations, climate modeling, and other data-intensive applications.
3. Generative AI
Powering next-gen AI applications in content creation, drug discovery, and more.
Benchmarks and comparisons
NVIDIA has released some impressive benchmarks for the H200:
- 40% faster inference performance on Llama 2 13B compared to H100
- 90% faster performance on Llama 2 70B
While we'll need to see more real-world benchmarks, these numbers suggest a significant leap forward in AI compute capabilities.
NVIDIA DGX systems: scalable AI infrastructure
NVIDIA's DGX systems take GPU acceleration to the next level, offering integrated solutions for AI research and enterprise deployment.
Specifications and scalability
- GPUs: 8x NVIDIA H100 Tensor Core GPUs
- GPU Memory: 640 GB total
- Performance: Up to 32 petaFLOPS AI (FP8)
- Networking: 400 Gb/s InfiniBand
What's impressive about DGX systems is their scalability. They can be clustered into DGX SuperPODs, delivering exaFLOPS of AI performance for the most demanding workloads.
Best applications
DGX systems are best in scenarios requiring massive AI compute:
1. AI research
Pushing the boundaries of what's possible in deep learning and neural networks.
2. Enterprise AI
Powering large-scale AI initiatives in industries like finance, healthcare, and manufacturing.
3. Autonomous systems
Training and simulating complex AI models for self-driving cars and robotics.
Let's look at some real-world examples of DGX systems in action:
Meta: Leveraged DGX systems to build the AI Research SuperCluster, one of the world's fastest AI supercomputers. This system is used for training massive language models and advancing AI research.
For enterprises considering their AI infrastructure options, NVIDIA's offerings provide a compelling mix of raw performance, scalability, and ecosystem support.
Comparative analysis

NVIDIA H200 is a specific hardware accelerator, not a full platform. It can be integrated into various cloud platforms and on-premises systems.
Performance and cost-efficiency metrics can vary significantly based on specific workloads and optimizations.
The best choice for an enterprise depends on its specific needs, budget, and technical expertise.

I also host an AI podcast and content series called “Pioneers.” This series takes you on an enthralling journey into the minds of AI visionaries, founders, and CEOs who are at the forefront of innovation through AI in their organizations.
To learn more, please visit Pioneers on Beehiiv.
Wrapping up
As we've explored the AI hardware landscape across AWS, Google Cloud, Azure, and NVIDIA, it's clear that each platform offers unique strengths for enterprise AI applications.
- AWS Trainium2 and Inferentia2 excel in cost-effective AI training and inference
- Google's TPU v4 and v5e offer impressive performance for large-scale AI workloads
- Azure's integration with NVIDIA GPUs provides a robust solution for diverse AI tasks
- NVIDIA's H200 and DGX systems push the boundaries of AI compute capabilities
Here’s what I recommend if you’re building enterprise AI systems:
- For complex, large-scale AI: Consider NVIDIA DGX systems or Google TPU pods
- For cost-efficient inference: AWS Inferentia2 or Google TPU v5e are strong options
- For Microsoft ecosystem integration: Azure's AI offerings provide seamless solutions
I’ll see you next week with more on building enterprise AI.
Until then,
Ankur.
Informative!