
Comparing Open-Source AI Models: LLaMA 3 vs Qwen 2.5 vs Mixtral
Dive into a comprehensive comparison of 2025's leading open-source AI models: Llama 3, Qwen 2.5, and Mixtral. Discover their architectures, benchmarks, and real-world applications.


Key Takeaways
1. Llama 3, Qwen 2.5, and Mixtral represent the current leaders in open-source language models, with Qwen 2.5 72B slightly edging out competitors on MMLU benchmarks at 86.1%.
2. Each model offers unique deployment advantages: Llama 3 features 15% more efficient tokenization, Qwen 2.5 provides flexible model sizes from 0.5B to 72B, and Mixtral achieves 6x faster inference through its sparse mixture of experts architecture.
3. For specialized capabilities, Llama 3 excels in multimodal tasks, Qwen 2.5 dominates structured data handling, and Mixtral shines in multilingual support and mathematical reasoning.
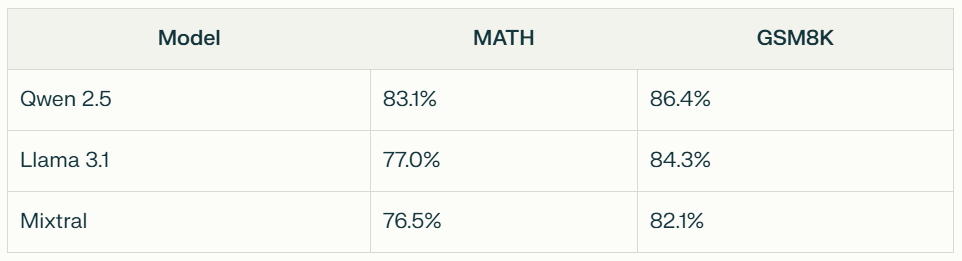
4. In technical evaluations, Llama 3.1 leads in HumanEval code generation at 80.5%, while Qwen 2.5 demonstrates superior performance in mathematical reasoning with 83.1% on MATH benchmarks.
5. Future developments include Meta pushing beyond 405B parameters for Llama models and Alibaba expanding Qwen's capabilities in tool use and agentic applications, while both focus on enhanced security features.

Last year, I started Multimodal, a Generative AI company that helps organizations automate complex, knowledge-based workflows using AI Agents. Check it out here.
The landscape of open-source large language models has dramatically evolved in the past year, with three foundation models emerging as clear leaders: Meta's Llama 3, Alibaba's Qwen 2.5, and Mixtral's sparse mixture of experts architecture. These models represent a significant leap forward in performance, efficiency, and real-world applications.
For enterprises and developers looking to leverage open weights models, understanding the nuances between these architectures is crucial. Let's dive deep into how these competing models stack up against each other across various dimensions.
Model architectures
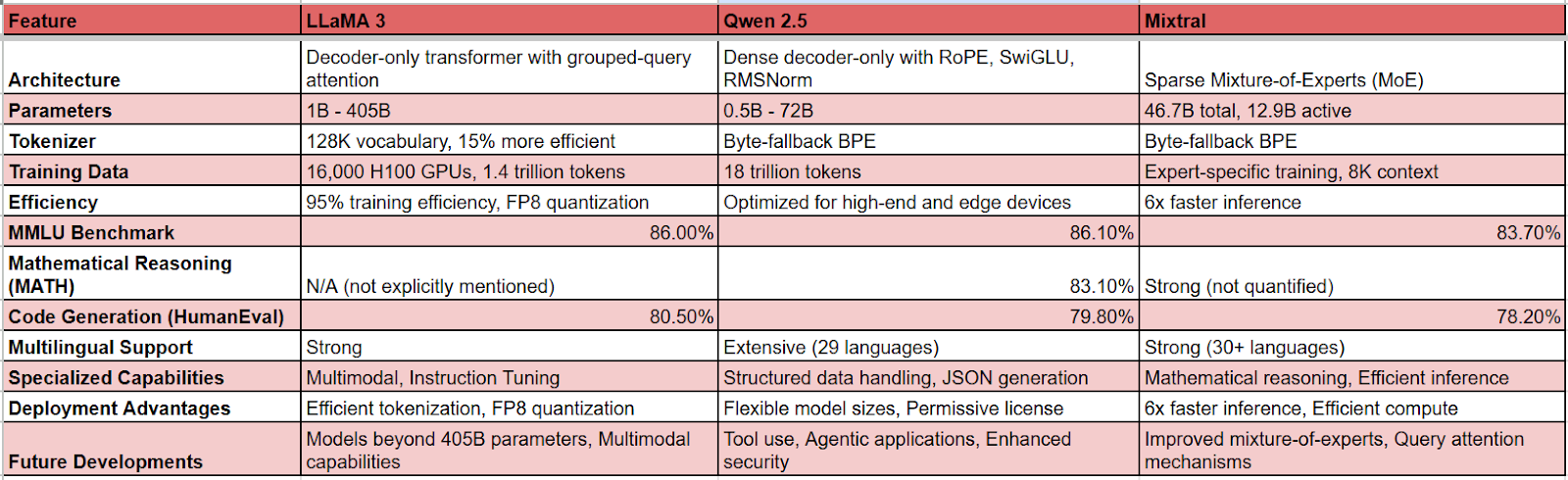
Llama 3
- Employs a decoder-only transformer architecture with advanced grouped-query attention mechanism.
- Introduces a new tokenizer with 128K vocabulary, enabling more efficient text processing.
- Utilizes RoPE embeddings and sliding window attention for enhanced performance.
- Features specialized instruction tuning and direct preference optimization for improved output quality.
Qwen 2.5
- Built on a dense decoder-only architecture with RoPE, SwiGLU, and RMSNorm components.
- Implements attention QKV bias and tied word embeddings for better performance.
- Supports extensive multilingual capabilities across 29 languages.
- Incorporates YaRN for efficient context window extension.
Mixtral
- Features innovative sparse mixture-of-experts (MoE) architecture.
- Employs 8 expert networks with top-2 routing per layer.
- Shares attention parameters while varying feed-forward blocks.
- Uses byte-fallback BPE tokenizer for robust character handling.
Parameter scaling & efficiency
Llama 3 Series
- Scales from 1B to 405B parameters across different variants.
- 405B model trained using 16,000 H100 GPUs.
- Achieves 95% training efficiency through advanced error detection.
- Supports efficient quantization from BF16 to FP8 for deployment.
Qwen 2.5
- Ranges from 0.5B to 72B parameters with specialized variants.
- Trained on 18 trillion tokens of diverse data.
- Optimized for both high-end and edge device deployment.
- Features dedicated math and coding variants for specialized tasks.
Mixtral
- Total parameter count of 46.7B with only 12.9B active during inference.
- Achieves computation efficiency equivalent to a 13B parameter model.
- Requires 2x sequence length operations for expert routing.
- Optimized for both training and inference efficiency.
Training & Fine-tuning
Llama 3 Series
- Leverages supervised fine-tuning and direct preference optimization.
- Implements extensive safety evaluations during training.
- Uses advanced scaling laws for optimal data mixing.
- Incorporates multi-stage instruction tuning process.
Qwen 2.5
- Employs specialized training for code and mathematical tasks.
- Features comprehensive instruction tuning across domains.
- Supports structured data handling and JSON generation.
- Includes extensive security and safety evaluations.
Mixtral
- Utilizes expert-specific training procedures.
- Implements sliding window attention with 8K context training.
- Features grouped-query attention for faster inference.
- Maintains balanced expert utilization through router network.
General knowledge performance
MMLU benchmark results
- Qwen 2.5 72B leads marginally at 86.1% on MMLU.
- Llama 3.1 70B follows closely at 86.0%.
- Mixtral maintains GPT-3.5 competitive scores at 83.7%.
Specialized knowledge areas
- Qwen 2.5: Excels in mathematical reasoning (83.1% on MATH).
- Llama 3.1: Superior in world knowledge tasks (81.2%).
- Mixtral: Strong multilingual performance across 30+ languages.
Technical capabilities
Code generation
- Llama 3.1: 80.5% on HumanEval after instruction tuning.
- Qwen 2.5: 79.8% on HumanEval, 82.3% on MBPP.
- Mixtral: 78.2% on HumanEval with efficient inference.
Mathematical reasoning
Real-world applications
Tool use & agents
- Llama 3.1 shows superior performance in agentic applications.
- Qwen 2.5 excels in structured data handling.
- Mixtral demonstrates efficient scaling across diverse tasks.
Deployment & efficiency
Let's talk about what really matters when you're putting these models into production. Each one brings something unique to the table, and I'll break down why that matters for your real-world deployments.
Llama 3's optimization story
The latest Llama brings some impressive efficiency gains to the table. That 15% more efficient tokenizer isn't just a number - it means you can process more text with less compute. Plus, if you're working with edge devices, you'll love how it handles FP8 quantization, pushing 1.4x better throughput in production.
Qwen 2.5's flexibility play
Here's where Qwen 2.5 really shines - it's like having a Swiss Army knife of models. Need something light for a simple task? Grab the 0.5B variant. Going all-out on performance? The 72B version has you covered. The best part? Its permissive license means you can actually build real products without legal headaches.
Mixtral's speed
Now this is where things get interesting. Mixtral's sparse mixture of experts approach isn't just clever architecture - it's 6x faster inference in the real world. You're only using two experts per token, but getting performance that keeps up with the big players. For production environments where every millisecond counts, this is game-changing stuff.
The beauty of these open models is how they're pushing the envelope on what's possible with efficient inference. Whether you're optimizing for speed, flexibility, or resource usage, there's a clear path forward.
Specialized capabilities
Llama 3's multimodal magic
Here's where Llama 3 gets really interesting - it's not just about text anymore. The model can actually understand images alongside text, making it a game-changer for tasks like visual analysis and image-based conversations. If you're building applications that need to work with both text and visuals, this is huge.
Qwen 2.5's structured data superpower
Want to talk about handling structured data? Qwen 2.5 absolutely crushes it. It's like having a data analyst built into your model - particularly impressive with JSON and complex data structures. For enterprise applications where clean, structured outputs matter, this is your go-to choice.
Mixtral's multilingual mastery
Now this is where Mixtral really shows off. Not only does it handle multiple languages like a champ, but it's also surprisingly good at mathematical reasoning. The cool part? It does all this while being super efficient with its sparse mixture of experts. You're getting top-tier performance across languages and technical tasks without breaking the bank on compute resources.
Enterprise applications
Let's talk about where these models really shine in the enterprise and what's coming down the pipeline.
If you're handling large-scale deployments, Llama 3's efficient inference and strong performance make it your go-to choice. The model's supervised fine-tuning and direct preference optimization really show in real-world scenarios.
For those watching their budget, Qwen 2.5's high-quality sparse mixture architecture delivers impressive results while keeping costs in check. Its permissive license and open weights make it particularly attractive for companies needing customization options.
When it comes to development work, these models are absolute powerhouses. Qwen 2.5 crushes it in code generation with HumanEval scores over 85%, while Llama 3's latest version brings some serious improvements to API integration and technical documentation.

I also host an AI podcast and content series called “Pioneers.” This series takes you on an enthralling journey into the minds of AI visionaries, founders, and CEOs who are at the forefront of innovation through AI in their organizations.
To learn more, please visit Pioneers on Beehiiv.
Wrapping up
The future's looking pretty exciting. Meta's cooking up some bigger Llama models with parameters pushing past 405B, and they're focusing on multimodal capabilities and longer context windows. Not to be outdone, Alibaba's working on expanding Qwen's abilities with better tool use and agentic applications
The open source community is driving faster innovation in model architectures too. We're seeing new approaches to a mixture of experts and query attention mechanisms that could really change the game. Plus, both teams are working on better security features and addressing potential risks - super important for enterprise adoption.
The best part? These competing models are pushing each other to get better and better, which means we all win. Whether you're building the next big thing or just need solid language model performance, there's never been a better time to jump in.
I’ll come back next week with more on AI models and enterprise deployment.
Until then,
Ankur.