
Comparing AI Cloud Providers in 2025: Coreweave, Lambda, Cerebras, Etched, Modal, Foundry and New Entrants
Read for a thorough comparison of cloud AI providers like Coreweave, Lambda, Cerebras, Etched, Modal, Foundry, and some new entrants in this space.


Key Takeaways
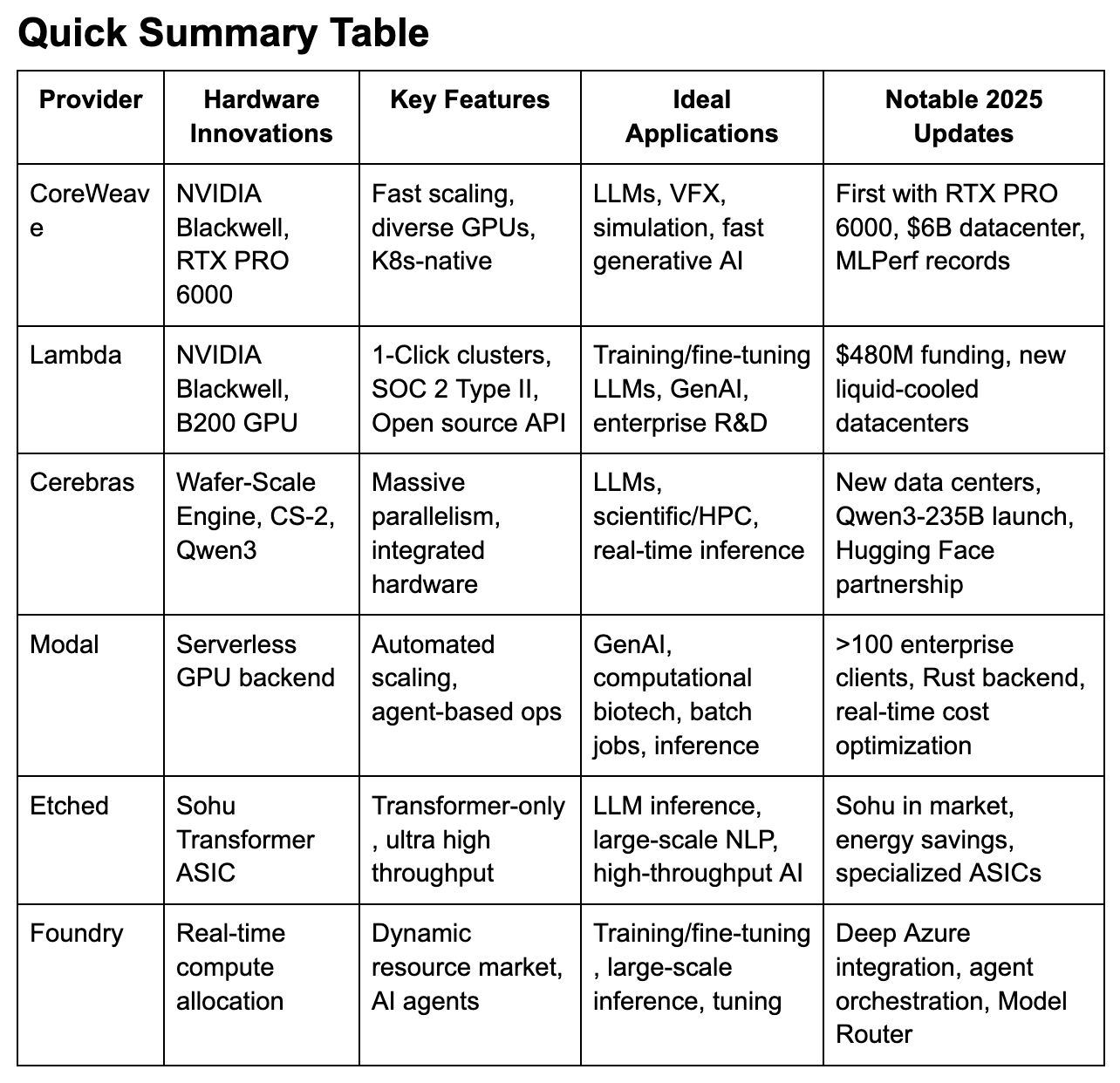
CoreWeave and Lambda Labs lead in GPU-accelerated AI training and inference, offering top-tier hardware like NVIDIA Blackwell and B200 with flexible cost-effective scaling.
Cerebras delivers unmatched performance for large-scale LLMs and scientific computing with its Wafer-Scale Engine (WSE), ideal for highly parallel workloads.
Modal and Foundry are redefining developer experience with serverless and real-time agent-based platforms that abstract away infrastructure complexity.
Etched’s transformer-specific Sohu ASIC dramatically reduces energy and hardware needs for LLM inference, but is only suited for transformer-based models.
Choosing the right provider depends on matching AI workload types (training, inference, deployment) with each platform’s strengths in performance, pricing, and specialization.

In 2023, I started Multimodal, a Generative AI company that helps organizations automate complex, knowledge-based workflows using AI Agents. Check it out here.
The AI cloud landscape has rapidly evolved, with both hyperscalers and specialized AI cloud providers pushing the boundaries of scalable, high-performance compute. Below, you'll find a current, detailed comparison of the top dedicated AI cloud platforms—CoreWeave, Lambda, Cerebras, Etched, Modal, and additional notable entrants—covering their features, performance, and best-suited use cases for enterprise AI.
1. CoreWeave
Overview: CoreWeave leads among AI-first clouds by offering rapid resource scaling (instances in seconds), a rich ecosystem of the latest NVIDIA GPUs (including Blackwell series), and advanced networking (NVIDIA Quantum InfiniBand).
Recent Upgrades: In 2025, became the first to offer NVIDIA RTX PRO 6000 Blackwell Server Edition at scale. MLPerf results show up to 5.6x faster LLM inference, and a $6B PA data center expansion solidifies its U.S. infrastructure.
Applications: Ideal for LLM training, VFX rendering, financial and scientific simulations, and generative AI at massive scale.
Cost: Up to 80% cheaper than general-purpose clouds, with flexible usage-based billing.
2. Lambda Labs
Overview: Lambda specializes in developer-friendly GPU clouds for LLM training, inference, and open-source deployments. Its SOC 2 Type II compliance appeals to enterprise users.
Recent Upgrades: Raised $480M in 2025, expanded to liquid-cooled AI data centers supporting NVIDIA Blackwell/Ultra. Launched 1-Click Clusters for seamless, on-demand scale, and Lambda Inference API for hosted LLMs.
Applications: Best for startups and R&D teams training/fine-tuning large models, generative AI development, and enterprise-scale inference.
Cost: Transparent pricing (A100: $1.25/hr, H100: $2.49/hr) with “one GPU per user” ethos.
3. Cerebras
Overview: Famous for the Wafer-Scale Engine (WSE), Cerebras packs unparalleled compute density for AI—2.6T+ transistors and 850,000 AI cores in a single chip.
Recent Upgrades: Deployed 6 new data centers (North America/France), launched Qwen3-235B (frontier LLM) at 1/10th the cost of closed models, deep integration with Hugging Face for inference hosting.
Applications: Unmatched for LLM and scientific simulation, medical/drug discovery, and workloads requiring fast, massive inference and modeling.
Differentiator: Efficient mixture-of-experts LLMs, high context window (up to 131K), deep cost savings for production deployment.
4. Modal
Overview: Modal eliminates DevOps headaches with serverless, containerized, GPU-backed compute—ideal for organizations that want to focus on code, not infrastructure.
Recent Upgrades: >100 enterprise clients, dynamic scaling driven by agents, Rust backend for rapid, pre-configured launches.
Applications: Best for rapid generative AI inference, computational biotech workloads, automated transcription, and batch analytics jobs.
Cost: Pay-as-you-go usage model with aggressive optimization for job cost and latency.
5. Etched
Overview: Etched's Sohu chip is a transformer-specific ASIC, achieving ultra-high performance for LLM inference—up to 500,000 tokens/sec for Llama-70B—which can replace up to 160 H100s in one 8xSohu box.
Recent Upgrades: Entered the market in 2025, addressing high energy use by leveraging specialization; >90% FLOPS utilization.
Applications: Only for transformer-based inference—chatbots, real-time NLP, and high-throughput services.
Cost & Efficiency: Large energy and space savings; only worth it for workloads that are 100% transformer-aligned.
6. Foundry (Microsoft Azure AI Foundry)
Overview: Microsoft’s Azure AI Foundry is a “real-time compute market” and LLM ops platform, tightly integrated with Azure cloud.
Recent Upgrades: Supports Grok and advanced models, AI Agent workflow tools, robust monitoring, and the Model Router that auto-selects the best model for each query. Dramatically improved developer tooling in 2025.
Applications: Real-time LLM training/inference, agent-based enterprise automation, hyperparameter tuning, industry cloud integrations.
Differentiator: Multi-agent orchestration, robust agent lifecycle management, deep integration with Microsoft’s enterprise tech stack.
Additional Notable Players
Spectro Cloud: Rapidly rising in composable infrastructure for AI workloads, appearing alongside Lambda and CoreWeave as a high-growth upstart.
Cloudera, AWS (Trainium/Inferentia), Google Cloud (Gemini): Remain strong but less differentiated on AI-specific hardware—however, provide best-in-class multicloud integration and enterprise support.
Groq, Perceive: Newcomers focusing on transformer-optimized and low-energy AI inference chips emerging as potential Etched competitors.
Market and Technology Trends in 2025
AI hardware diversity: Blackwell, WSE, B200, Sohu, and cloud ASICs are driving faster, cheaper, and greener AI infrastructure.
Specialization pays: Transformer-specific platforms (Etched, Groq) are converging on the inference boom; generic clouds differentiate with scale and integration.
Enterprise shift: SOC2/ISO compliance and direct LLM inference APIs are now must-haves for enterprise adoption.
Cloud spend soars: AI now drives an estimated half of new cloud revenue, with spending expected to surpass $723B globally in 2025.
Agent-driven ops: Serverless and agent-based operation models (Modal, Foundry) slash dev time and reduce infrastructure friction.

I also host an AI podcast and content series called “Pioneers.” This series takes you on an enthralling journey into the minds of AI visionaries, founders, and CEOs who are at the forefront of innovation through AI in their organizations.
To learn more, please visit Pioneers on Beehiiv.
How to Choose the Right Provider
Match your workload: LLM training or VFX = CoreWeave/Lambda; transformer inference = Etched; fast, serverless deployment = Modal; massive parallel compute = Cerebras; integrated enterprise workflows = Foundry.
Consider cost vs. performance: CoreWeave and Lambda offer leading price/performance for GPU-heavy jobs.
Future-proofing: Look for rapid hardware releases (Blackwell, new ASICs), ecosystem fit, and compliance capabilities.
Integration: Consider how well a provider fits into your existing stack, especially if leveraging Azure/Microsoft or hybrid cloud models.
AI-first clouds are complementing (and sometimes outpacing) the hyperscalers with rapid hardware innovation and a laser focus on high-performance AI workloads—a trend that is only expected to accelerate throughout 2025 and beyond.