
4 Techniques for Retrieval Augmented Generation (RAG)
Compare different Retrieval Augmented Generation (RAG) techniques including implementation methods, best practices, and challenges to overcome.


Key Takeaways
1. Retrieval Augmented Generation (RAG) is essential for effective enterprise AI implementation, enhancing information retrieval and overcoming limitations of traditional large language models.
2. Four main RAG techniques include traditional document-based, vector database, hybrid, and multimodal approaches, each with unique strengths and applications.
3. Choosing the right RAG method depends on an enterprise's specific needs, data types, and computational resources.
4. Successful RAG implementation requires careful consideration of data quality, security, scalability, and integration with existing systems.
5. Best practices for RAG deployment include prioritizing data management, investing in security, embracing an API-first approach, and starting with pilot projects before full-scale implementation.

Last year, I started Multimodal, a Generative AI company that helps organizations automate complex, knowledge-based workflows using AI Agents. Check it out here.
Retrieval Augmented Generation (RAG) is key to enterprises unlocking AI implementation and making their workflows smoother and more efficient. Generative AI is truly the future of work, but for it to be effective for complex knowledge work, techniques like RAG are crucial.
Let’s dive into some of the most effective ways to do RAG, and how you should think about it if you’re trying to build AI systems for enterprises.
Why enterprise AI needs RAG

Large language models are excellent at doing complex tasks really fast. But because of their huge training database and complicated architecture, they’re not very relevant for enterprise applications without some tweaking. Here’s why I recommend every enterprise AI builder to engage with RAG:
1. Enhanced information retrieval: RAG combines large language models (LLMs) with external knowledge sources, providing accurate and contextually relevant responses to user queries.
2. Overcoming LLM limitations: Traditional LLMs often struggle with real-time or domain-specific inquiries. RAG addresses this by integrating up-to-date information.
3. Streamlined workflows: In finance and insurance, RAG systems can integrate structured and unstructured data sources, improving decision-making processes.
RAG implementation methods
Depending on the way you’re going to use AI for your enterprise, the method of retrieval augmented generation you choose will also differ. Here are some typical RAG techniques enterprises use:
1. Traditional document-based RAG

This method forms the foundation of many RAG systems, especially in text-heavy industries. Here's what you need to know:
How it works
Document ingestion: The system ingests and processes documents from various sources, such as research reports, customer service guides, and web pages.
Indexing: Documents are indexed for efficient retrieval, often using keyword search or basic query techniques.
Retrieval: When a user submits a query, the system searches the indexed documents for relevant information.
Augmentation: Retrieved passages are used to augment the prompt given to the large language model (LLM).
Generation: The LLM generates a response based on the augmented prompt.
Pros
1. Simple implementation: Leverages existing document management systems, making it easier to adopt.
2. Familiarity: Works well with traditional information retrieval methods that many organizations already use.
3. Domain specificity: Excels in industries with extensive textual documentation, like insurance and finance.
Cons
1. Limited data types: Primarily works with unstructured text data, potentially missing insights from other data formats.
2. Real-time challenges: May struggle to incorporate up-to-date information if document repositories aren't frequently updated.
3. Scalability concerns: As the document library grows, retrieval speed and accuracy can be impacted without optimized search algorithms.
Enterprise applications
Policy document retrieval: Insurance companies can use this method to quickly access relevant policy information when addressing customer queries.
Financial report analysis: Investment firms can leverage RAG to extract key insights from vast repositories of financial reports and market analyses.
2. Vector database RAG
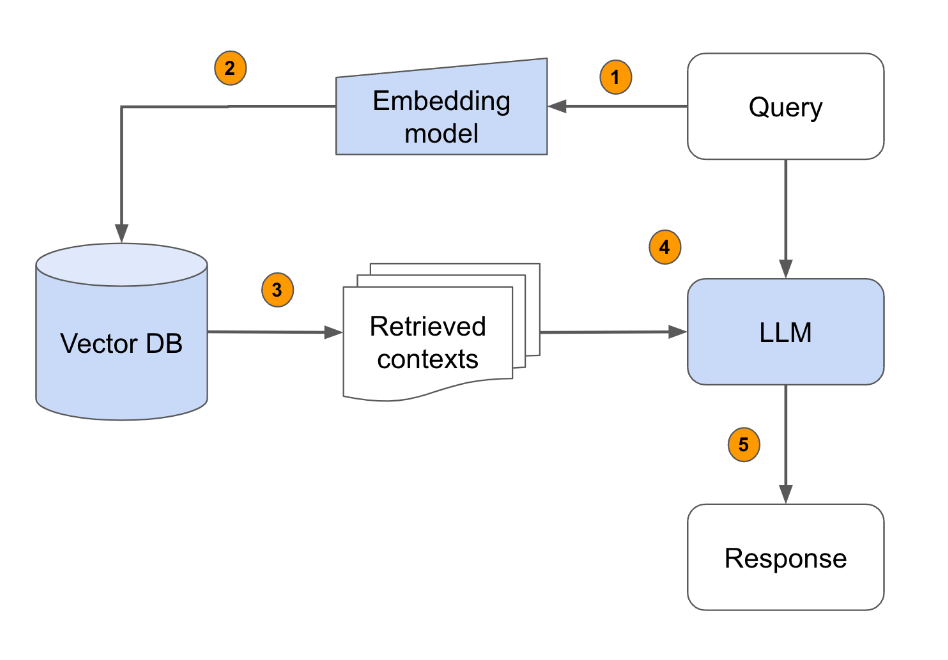
What are vector databases?
Vector databases are specialized systems designed to store and efficiently search high-dimensional numerical representations of data, known as embeddings. These embeddings capture the semantic meaning of information, allowing for more nuanced and context-aware retrieval compared to traditional keyword search methods.
How RAG leverages vector search capabilities
1. Embedding generation: When a user submits a query, it's converted into a vector embedding using an embedding model.
2. Similarity search: The system searches the vector database for the most similar embeddings to the query vector.
3. Retrieval: Relevant documents or data points associated with the similar embeddings are retrieved.
4. Augmentation: The retrieved information is used to augment the prompt sent to the large language model (LLM).
5. Response generation: The LLM generates a response based on the augmented prompt, combining its training data with the retrieved external knowledge.
Pros
1. Efficient semantic search: Vector databases excel at finding semantically relevant passages, even when exact keyword matches aren't present.
2. Handles diverse data types: From text and images to audio and video, vector databases can process and search various data formats.
3. Scalability: Designed to handle large datasets, making them suitable for enterprises with vast knowledge bases.
Cons
1. Initial setup complexity: Implementing this kind of RAG system requires careful planning and expertise in data transformation and embedding generation.
2. Periodic reindexing: To maintain optimal performance, the database may need regular updates and reindexing, especially when dealing with rapidly changing information.
3. Computational requirements: Vector search operations can be computationally intensive, potentially leading to higher infrastructure costs.
Enterprise applications
1. Real-time market data analysis in finance: Vector databases enable financial institutions to quickly process and analyze vast amounts of market data, news, and research reports. This allows for more accurate and timely investment decisions.
2. Customer profile matching in insurance: Insurance companies can use vector database RAG to match customer profiles with the most relevant policies or risk assessments.
Remember, while vector databases offer powerful capabilities, their successful implementation requires careful consideration of your specific use case, data types, and computational resources.
3. Hybrid RAG (combining structured and unstructured data)

This innovative approach to Retrieval Augmented Generation is transforming how businesses handle knowledge-intensive tasks and process complex user queries.
How it works
Hybrid retrieval augmented generation integrates traditional databases with unstructured data sources, creating a comprehensive knowledge ecosystem. Here's a breakdown of the process:
1. Data ingestion: The system ingests both structured data (e.g., from SQL databases) and unstructured data (e.g., documents, web pages, and customer service guides).
2. Unified indexing: A sophisticated indexing system creates a bridge between structured and unstructured data, often using vector databases for efficient retrieval.
3. Query processing: When a user submits a query, the system searches both structured and unstructured data sources simultaneously.
4. Relevance ranking: Using advanced algorithms, the system ranks the most relevant information from both data types.
5. Augmented prompt creation: The retrieved information is used to create an augmented prompt for the large language model (LLM).
6. Response generation: The LLM generates a comprehensive response based on the augmented prompt, leveraging both structured and unstructured data insights.
Pros
1. Comprehensive data utilization: Hybrid RAG taps into the full spectrum of enterprise data, from transactional records to unstructured text, providing a 360-degree view of information.
2. Enhanced accuracy: By combining structured data's precision with unstructured data's context, Hybrid retrieval augmented generation produces more accurate and nuanced responses.
3. Adaptability: This approach can be tailored to various enterprise data ecosystems, making it versatile across different industries and use cases.
Cons
1. Complex implementation: Integrating disparate data sources requires sophisticated data integration strategies and expertise.
2. Potential latency: Querying multiple data sources simultaneously may lead to increased response times, especially for complex queries.
3. Data governance challenges: Handling both structured and unstructured data raises concerns about data privacy and security, particularly when dealing with sensitive customer information.
Enterprise applications
1. Risk assessment in insurance: Hybrid RAG excels in combining structured policy data with unstructured external factors like weather reports, social media trends, and news articles. This comprehensive approach enables insurers to make more accurate risk assessments and offer personalized policies.
2. Fraud detection in finance: By analyzing structured transaction data alongside unstructured customer information (e.g., support tickets, social media activity), financial institutions can identify suspicious patterns more effectively.
3. Customer service enhancement: Hybrid retrieval augmented generation can provide customer service representatives with a holistic view of customer data, combining structured account information with unstructured interaction history. This enables more personalized and efficient support.
Hybrid RAG bridges the gap between structured and unstructured data, enabling organizations to unlock deeper insights, make more informed decisions, and provide superior services to their customers.
4. Multimodal RAG

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
This innovative approach extends the capabilities of traditional RAG systems by incorporating diverse data types, including text, images, and audio.
How it works
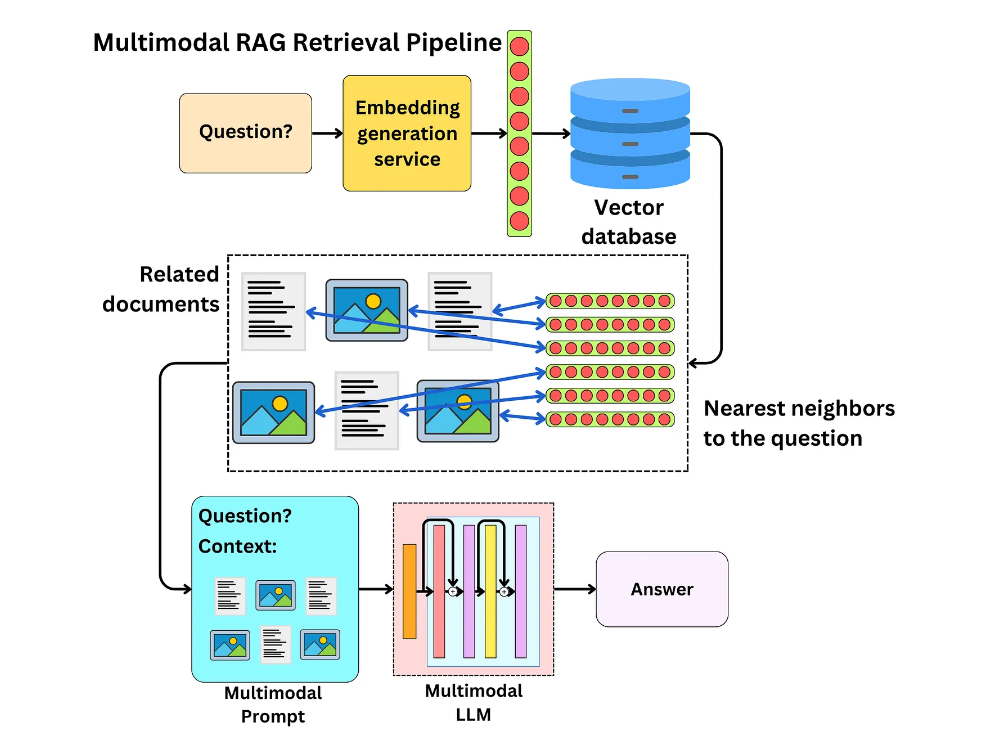
Multimodal RAG integrates various data formats into a unified retrieval and generation system:
1. Data ingestion: The system ingests diverse data types, including text documents, images, audio files, and even video content.
2. Multimodal embedding: Advanced embedding models convert different data types into a common vector space, allowing for unified indexing and retrieval.
3. Cross-modal retrieval: When a user submits a query (which can be text, image, or audio), the system searches across all data types to find relevant information.
4. Relevance ranking: Sophisticated algorithms rank the most relevant information across modalities.
5. Multimodal prompt creation: The retrieved information, regardless of its original format, is used to create an augmented prompt for the large language model (LLM).
6. Response generation: The LLM generates a comprehensive response, potentially incorporating insights from various data types.
Pros
1. Comprehensive data utilization: Multimodal RAG taps into a broader spectrum of enterprise data, providing a more holistic view of information.
2. Enhanced context understanding: By incorporating visual and audio data, the system can capture nuances that text alone might miss.
3. Improved accuracy in complex scenarios: For tasks requiring multi-faceted analysis, such as insurance claim assessment, multimodal RAG can provide more accurate and nuanced responses.
Cons
1. Increased complexity: Handling multiple data types requires more sophisticated algorithms and infrastructure, potentially increasing implementation challenges.
2. Higher computational requirements: Processing and analyzing diverse data formats can be computationally intensive, potentially leading to increased costs.
3. Data quality challenges: Ensuring consistent quality across different data types can be more challenging than with text-only systems.
Enterprise applications
1. Visual damage analysis: In auto insurance claims, the system can analyze photos of vehicle damage alongside textual claim descriptions, providing more accurate assessments.
2. Audio statement processing: For personal injury claims, the system can transcribe and analyze audio statements from claimants, witnesses, and experts, correlating this information with written reports and visual evidence.
3. Document verification: The system can cross-reference handwritten claim forms with typed documents and database records, flagging discrepancies more effectively.
4. Fraud detection: By analyzing patterns across text, image, and audio data, the system can identify potential fraudulent claims more accurately than text-only systems.
5. Real-time claim estimation: Adjusters in the field can submit photos and voice notes, receiving instant preliminary assessments based on historical claim data and visual analysis.
Multimodal RAG represents a significant leap forward in enterprise AI capabilities, particularly for industries like insurance that deal with diverse data types.
Comparative analysis

When evaluating RAG implementation methods for enterprise use, it's essential to consider various factors that can impact performance, scalability, and integration capabilities. Let's break down how traditional document-based RAG, vector database RAG, hybrid RAG, and multimodal RAG compare across key metrics:
Implementation complexity: Traditional document-based RAG is relatively straightforward to implement, especially for organizations with existing document management systems. On the other hand, multimodal RAG requires sophisticated algorithms and infrastructure to handle diverse data types, making it the most complex to implement.
Scalability: Vector database RAG, hybrid RAG, and multimodal RAG all offer high scalability, thanks to their efficient indexing and retrieval mechanisms. Traditional document-based RAG may face challenges with very large document sets.
Data type handling: Multimodal retrieval augmented generation excels here, capable of processing text, images, and audio. Hybrid RAG follows closely, adept at handling both structured and unstructured data. Vector database RAG is primarily focused on text and structured data, while traditional document-based RAG is limited mostly to text.
Real-time capabilities: Vector database retrieval augmented generation, hybrid RAG, and multimodal RAG all offer strong real-time capabilities, crucial for applications like real-time market data analysis in finance or instant claim assessment in insurance. Traditional document-based RAG may lag slightly in this area.
Integration with existing systems: Traditional document-based RAG often integrates seamlessly with existing document management systems. Hybrid RAG also tends to integrate well, given its ability to work with both structured and unstructured data sources. Vector database and multimodal RAG may require more adaptation of existing systems.
When choosing between these techniques, my first step is to analyze the nature of the enterprise and the key workflows it wants a solution for. For example, a financial institution dealing primarily with textual data might find vector database RAG sufficient, while an insurance company handling diverse data types for claim assessment might benefit more from multimodal RAG.
Best practices for enterprise RAG implementation
1. Choosing appropriate knowledge sources
- Identify relevant internal and external data sources
- Prioritize high-quality, up-to-date information
- Consider domain-specific knowledge bases
2. Data preparation and management
- Clean and structure data for optimal retrieval
- Implement robust data governance policies
- Regularly update and maintain knowledge libraries
3. Fine-tuning strategies
- Adapt large language models to your specific domain
- Use domain-specific training data for better performance
- Continuously refine models based on user feedback
4. Updating and maintaining knowledge libraries
- Establish processes for regular content updates
- Implement version control for knowledge bases
- Monitor and evaluate retrieval performance
Challenges and considerations
While RAG offers significant benefits, enterprises must navigate several challenges:
1. Scalability and performance optimization
- Design systems to handle increasing data volumes
- Optimize retrieval algorithms for faster response times
- Balance computational costs with performance requirements
2. Data privacy and security
- Implement robust encryption for sensitive data
- Ensure compliance with data protection regulations
- Manage access controls for personally identifiable information
3. Integration with existing enterprise systems
- Develop APIs for seamless integration
- Ensure compatibility with legacy systems
- Address potential conflicts with existing workflows

I also host an AI podcast and content series called “Pioneers.” This series takes you on an enthralling journey into the minds of AI visionaries, founders, and CEOs who are at the forefront of innovation through AI in their organizations.
To learn more, please visit Pioneers on Beehiiv.
Wrapping up
If you’re looking to implement RAG in your enterprise, here’s what I recommend you keep in mind:
1. Prioritize data quality and management: Ensure your data sources are accurate, up-to-date, and well-structured. Implement regular data cleaning and updating processes to maintain the integrity of your knowledge base.
2. Invest in robust security measures: Implement strong encryption, access controls, and data masking techniques to protect sensitive information. Regularly audit your RAG system for potential vulnerabilities.
3. Focus on scalability: Design your RAG architecture with growth in mind. Consider cloud-based solutions or hybrid approaches that can easily scale with your needs.
4. Embrace an API-first approach: This ensures seamless integration with existing systems and allows for greater flexibility as your needs evolve.
5. Implement fine-tuning strategies: Adapt your RAG model to your specific domain for improved performance and relevance.
6. Address ethical considerations: Be mindful of potential biases in your data and model outputs. Implement safeguards to ensure fair and ethical use of the technology.
7. Invest in employee training: Ensure your team has the necessary skills to manage and maintain your RAG system effectively.
8. Start small and iterate: Begin with pilot projects to gain experience and refine your approach before full-scale implementation.
9. Prioritize user experience: Design your RAG-powered applications with a focus on user-friendliness and intuitive interactions.
10. Stay compliant: Ensure your RAG implementation adheres to relevant data privacy regulations and industry standards.
Next week, we will explore more about enterprise AI and agentic automation.
Until then,
Ankur